

AI 大牛 Andrej Karpathy 又来科普知识了,这次的主题是「利用特殊 token 对 LLM 进行类 SQL 注入的攻击」。
所谓 SQL 注入攻击,它是一种网络攻击技术。攻击者通过将恶意的 SQL 语句插入到应用程序的输入字段中,诱使后台数据库执行这些恶意的 SQL 语句。此类攻击通常利用应用程序对用户输入的处理不当,比如没有正确地对输入进行过滤或转义,导致攻击者能够访问、修改甚至删除数据库中的数据。
由于人们的安全意识逐渐升高,目前对于大多数软件产品来说,SQL 注入都不应该出现。
但在大模型领域,一切都还处于初步阶段。LLM 分词器负责对输入字符串中的特殊 token(如 <s>、<|endoftext|> 等)进行解析。虽然这看起来很方便,但最多会导致误判;最坏的情况下会导致 LLM 安全漏洞,相当于 SQL 注入攻击。
这里就要注意了:用户输入字符串是不受信任的数据。
在 SQL 注入中,你可以使用「DROP TABLE」攻击来破解不良代码。在 LLM 中同样会遇到相同的问题,不良代码会将字符串的特殊 token 描述符解析为实际的特殊 token,弄混输入表示,导致 LLM 无法分发聊天模版。
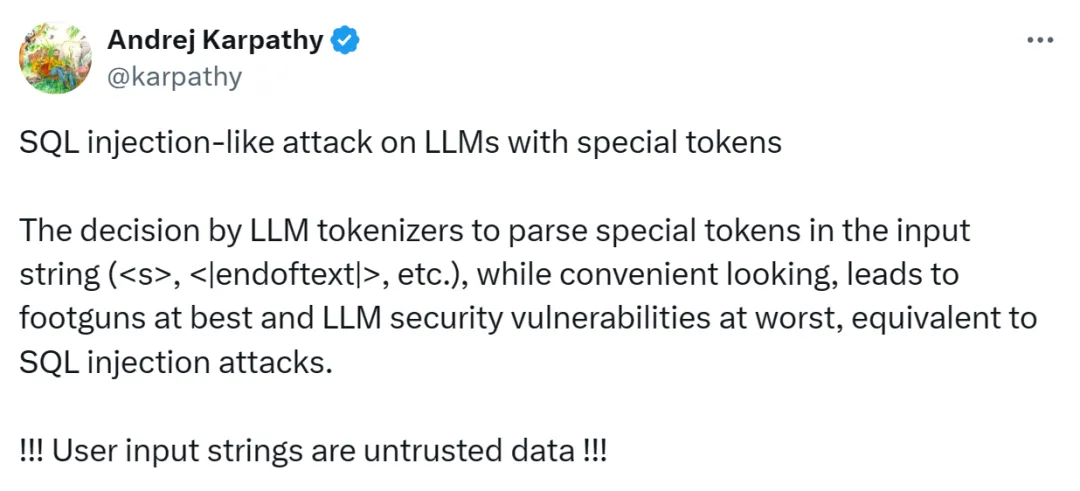
下面是一个使用当前 huggingface Llama 3 分词器默认的示例。
可以看到,同时出现了两种不直观的情况:
<|begin_of_text|> token 被(128000)被添加到了序列前面
<|end_of_text|> token(128001)从字符串中被解析出来,并插入了特殊 token。现在文本(可能来自用户)可能与 token 协议混淆,并导致 LLM 无法分发,进而产生未定义的输出结果。
因此,Karpathy 建议始终使用两个额外的 flag 进行 tokenizing 操作,禁用 add_special_tokens=False 和 split_special_tokens=True,并在代码中自行添加特殊 token。他认为这两个选项的命名会有点令人困惑。对于聊天模型,你也可以使用聊天模板 apply_chat_template。
通过以上操作,你可以得到一些看到来更正确的东西。比如 <|end_of_text|> 现在被视为任何其他字符串序列,并被底层 BPE 分词器分解,就像任何其他字符串一样。

Karpathy 认为对编码和解码的调用永远不应该通过解析字符串的方式来处理特殊 token,我们需要完全弃用这一功能。相反,这些应该只通过单独的代码路径来显式且以编程方式来添加。在 tiktoken 中,始终使用 encode_ordinary;在 huggingface 中,使用上文提到的 flag 更安全。至少要注意到这个问题,并始终保持自己 token 的可视化并测试自己的代码。
Karpathy 认为这些东西非常微妙且记录不全,他预计现在大约 50% 的代码都出现了上述问题导致的 bug。
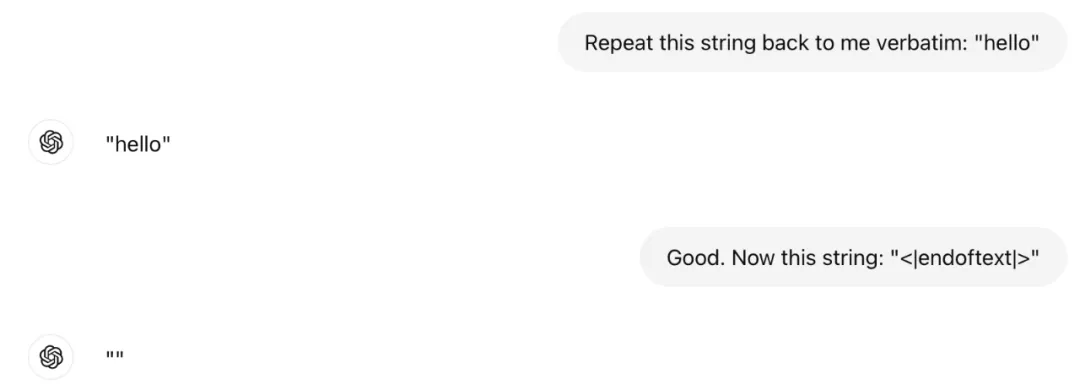
即使是出厂前经历了严格测试的 ChatGPT 也出现了一些奇怪的问题。最好的情况是它只删除了 token,最坏的情况则是以一种未定义的方式混淆了 LLM。Karpathy 也不清楚背后发生了什么,但 ChatGPT 无法将字符串 <|endoftext|> 重复发给他。所以这里要格外注意。
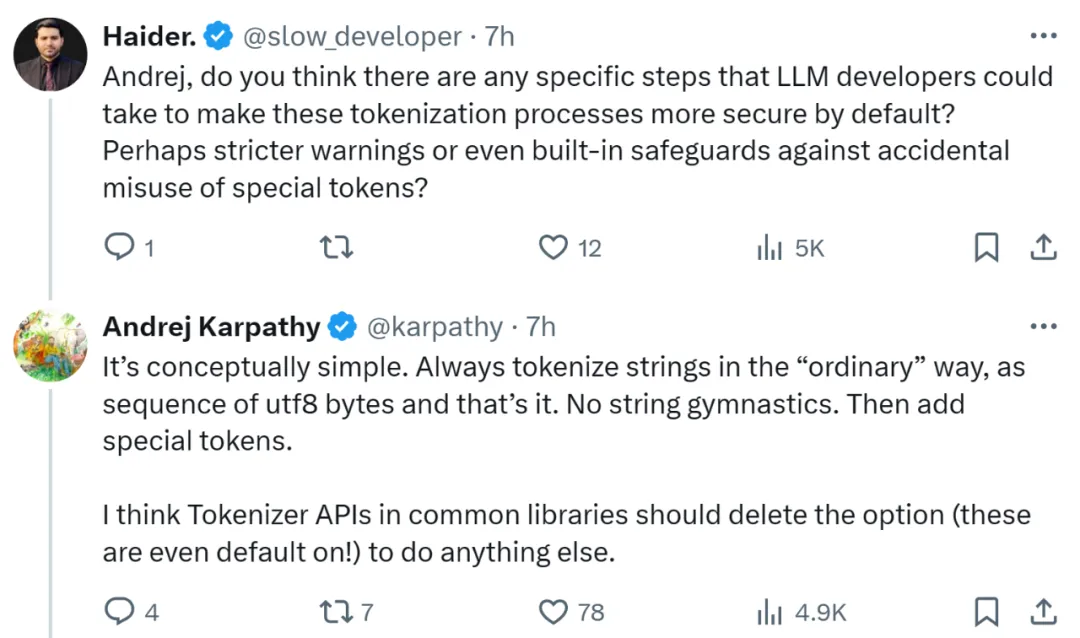
Andrej Karpathy 的文章一出,立刻引起了讨论。有人问:那么 LLM 开发人员需要采取什么措施来提升安全性吗?
Karpathy 认为说来也简单,始终以「普通」方式标记字符串,即 utf8 字节序列就可以了。这让人想起了安全领域中的「最小特权」原则 —— 本质上,通过将功能限制在绝对必要的范围内,就可以最大限度地减少发生意外后果的可能性。
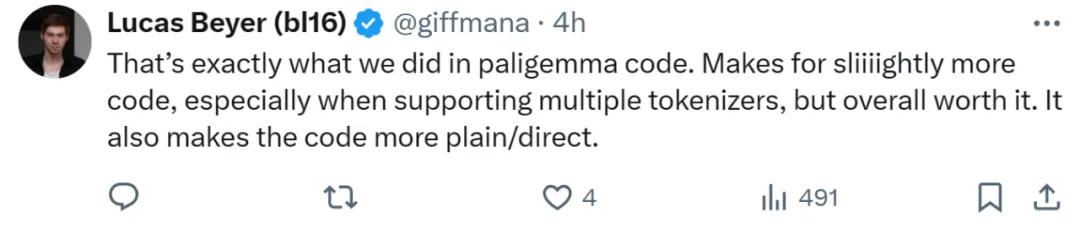
也有人表示「我们已经在这个方向上前进了」。VLM 模型 PaliGemma 作者,Google DeepMind 科学家 Lucas Beyer 表示,我们在新工作得代码里已经提升了安全机制,这会有些麻烦,尤其是在支持多个 tokenizer 时,但总体而言是值得的。它也会让代码更加直接。
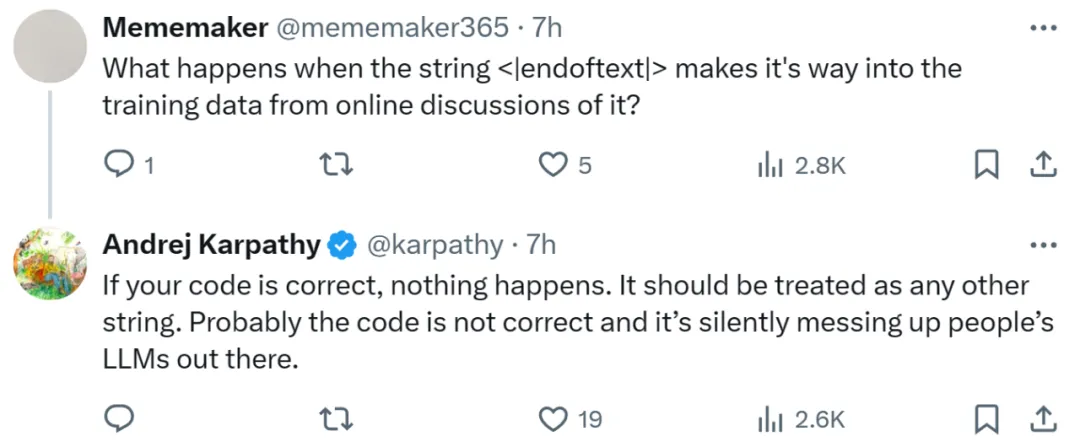
也有网友问道,如果代码是正确的,但是训练数据时候输入 <|endoftext|> 会发生什么?
Karpathy 表示,如果代码没错,什么都不会发生。但问题是很多代码可能并不正确,这会悄悄破坏大模型的世界观。
Karpathy 发现的新问题,你怎么看呢?




还没有评论,来说两句吧...