

我们知道,大模型面临的三大挑战是算法、算力和数据。前两者靠优化升级,后者靠积累。随着技术的不断发展,高质量数据已经逐渐成为最大的瓶颈。
在很多新模型上,人们为了提升模型能力,都采用了使用 AI 生成数据来训练的方式。人们普遍认为,使用合成数据可以显著提升模型质量。
不过,最新的研究认为,使用 AI 生成的数据并不是什么好办法,反而可能会让模型陷入崩溃。
今天发表在学术顶刊《自然》杂志的封面研究认为,如果放任大模型用自动生成的数据训练自己,AI 可能会自我退化,在短短几代内将原始内容迭代成无法挽回的胡言乱语。

这篇由牛津大学等机构提交的研究,强调了由于自我训练导致人工智能模型崩溃(Model Collapse)的风险,论证了原始数据源和仔细数据过滤的必要性。

论文链接:https://www.nature.com/articles/s41586-024-07566-y
哪种模型容易崩溃?
研究认为,当人工智能模型在生成的数据上进行过度训练时,就会发生不可逆转的模型崩溃。
「模型崩溃是指由于对合成数据进行不加区分的训练而导致模型崩溃的现象」,牛津大学研究员、该论文的主要作者 Ilia Shumailov 表示。
根据论文所述,大型语言模型等生成式 AI 工具可能会忽略训练数据集的某些部分,导致模型只对部分数据进行训练。
众所周知,大语言模型(LLM)需要巨量数据进行训练,从而使自身获得解释其中信息并应用于各种用例的能力。LLM 通常是为了理解和生成文本而构建的,但研究小组发现,如果忽略它据称正在阅读并纳入其知识库的大量文本,可能会很快地使 LLM 沦为空壳。
「在模型崩溃的早期阶段,模型首先会失去方差,在少数数据上的表现下降,在模型崩溃的后期阶段,模型则会完全崩溃」,Shumailov 说道。因此,随着模型继续在模型本身生成的越来越不准确和相关的文本上进行训练,这种递归循环会导致模型退化。
模型崩溃,到底是什么
在该论文中,作者发现的模型崩溃效应是一种退化过程,模型生成的数据会污染下一代模型的训练集。模型接受受污染数据的训练,会错误地感知现实,如下图 (a) 所示。
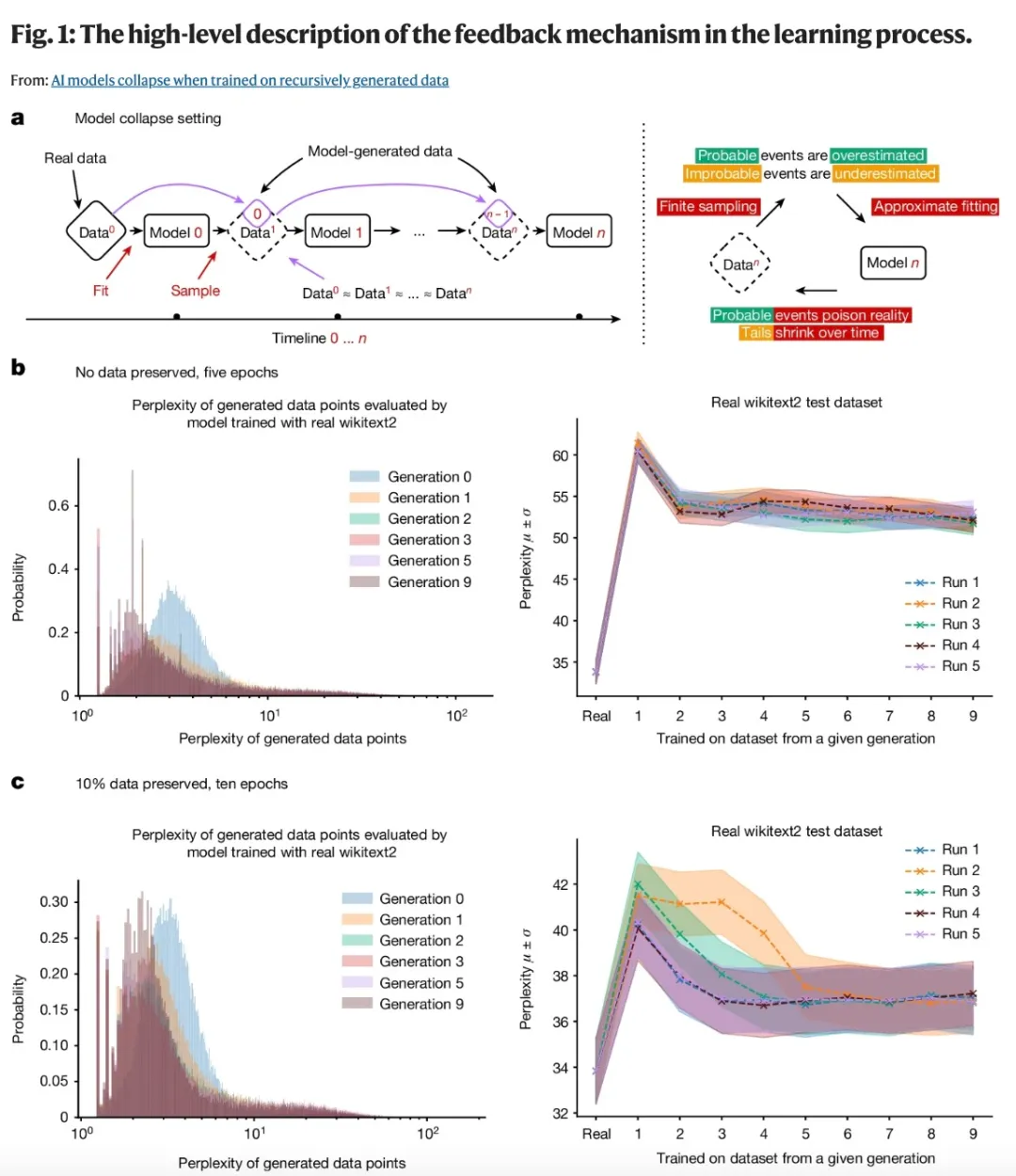
模型崩溃可以分为早期和后期阶段,早期模型会在少数数据上表现下降,后期模型会收敛到一种与原始分布几乎没有相似之处的分布,并且方差通常大大减少。
模型崩溃发生主要是因为下述三个特定误差源在几代模型中复合,并导致与原始模型出现较大偏差:
统计近似误差。这是由于样本数量有限而产生的主要误差,并且随着样本数量趋于无穷大而消失。发生这种情况是因为重采样的每一步都可能丢失信息。
函数表达误差。这是第二种类型的误差,是由于函数逼近器表达能力有限而产生的。特别是,神经网络只是通用逼近器,无法完美地逼近任何分布。神经网络可以在原始分布之外引入非零似然,或者在原始分布内引入零似然。函数表达误差的一个简单例子是,如果我们尝试用单个高斯拟合两个高斯的混合。即使我们有关于数据分布的完美信息(即无限数量的样本),模型误差也将是不可避免的。然而,在没有其他两种类型的误差的情况下,这种情况只能发生在第一代模型。
函数逼近误差。这是次要类型的误差,主要源于学习过程的局限性,例如随机梯度下降的结构偏差。
上述每一项都可能导致模型崩溃变得更糟或更好。更高的逼近能力甚至可以是一把双刃剑,更好的表达能力可以抵消统计噪声,从而很好地逼近真实分布,但它同样会加剧噪声。这通常会产生级联效应,其中个体的不准确性结合起来会导致整体误差增加。
例如,过度拟合密度模型会导致模型错误推断,将高密度区域分配给训练集未覆盖的低密度区域。
值得注意的是,还存在其他类型的误差。例如,计算机在实践中的精度有限。
语言模型中的模型崩溃
作者在文中还评估了模型崩溃对语言模型的影响。模型崩溃在各种机器学习模型中普遍存在。然而,与通常从零开始训练的小模型(如 GMMs 和 VAEs)不同,LLM 需要巨大的成本从头开始训练,因此通常使用预训练模型(如 BERT、RoBERTa 或 GPT-2)初始化,这些模型是在大型文本语料库上训练的。随后,这些模型被微调以适应各种下游任务。
在这篇论文中,作者探讨了当语言模型使用由其他模型生成的数据进行连续微调时会发生什么。本文中涉及的所有实验可以在非微调设置下用更大的语言模型轻松复制。鉴于训练一个中等规模的模型需要的算力也非常可观,作者选择不进行这样的实验,而是专注于更现实的概念验证设置。
需要注意的是,本文描述的语言实验即使在这种情况下也需要几周时间才能完成。作者评估了训练语言模型的最常见设置 —— 微调设置,其中每个训练周期都从一个具有最新数据的预训练模型开始。这里的数据来自另一个经过微调的预训练模型。由于训练被限制在生成与原始预训练模型非常相似的模型,并且这些模型生成的数据点通常只会产生非常小的梯度,因此预期在微调后,模型只会发生适度的变化。作者使用 Meta 通过 Hugging Face 提供的 OPT-125m 因果语言模型进行了微调。
案例研究:教堂和长耳大野兔
研究人员在论文中提供了一个使用文本生成模型 OPT-125m 的示例(使用 wikitext2 数据集微调),该模型的性能与 ChatGPT 的 GPT-3 类似,但需要的算力较少。
研究人员将有关设计 14 世纪教堂塔楼的文本输入到模型中。在第一代文本输出中,该模型主要讨论了在不同教皇统治下建造的建筑物。但到了第九代文本输出,该模型主要讨论了大量的黑尾、白尾、蓝尾、红尾和黄尾长耳大野兔。我们应该注意到的是,其中大多数并不是真正存在的长耳大野兔物种。

大模型输出的内容:从教堂到 100 多种语言,再到野兔。
实验结果表明,即使原数据一直保留,但模型崩溃的现象仍然会发生。随着不断迭代,模型开始忘记真实数据中的信息,并且生成的内容中包含越来越多重复的短语。
网络充斥 AI 内容,「数据源」早已被污染
看到这里你可能会问了:那还不简单,不使用合成数据训练 AI 不就完事了?但实际上,现在能从互联网上获取的「数据」,里面已经不知道有多少是 AI 生成的了,而且我们经常无法把它们和正常内容区分开来。
互联网上充斥着各种内容,这并不是新鲜事。正如研究人员在论文中指出的那样,早在大规模语言模型(LLM)成为公众熟知的话题之前,恶意网站就已经在制造内容,以欺骗搜索算法优先显示他们的网站以获取点击量。随着 OpenAI 的 GPT 系列大模型问世,生成式 AI 已经并将会极大地改变文本和图像内容的生态。
AI 生成文本可比人类说废话快得多,这引发了更大规模的担忧。杜克大学专门研究隐私与安全的计算机科学家艾米丽 - 温格 Emily Wenger 曾在文章中写到相关内容:「尽管 AI 生成的互联网对人类的影响还有待观察,但 Shumailov 等人报告称,在线上大量涌现的 AI 生成内容可能对这些模型本身造成毁灭性的影响。」
「模型崩溃带来的问题之一是对生成式 AI 的公平性构成挑战。崩溃的模型会忽略训练数据中的一些不常见元素,从而无法反映世界的复杂性和细微差别,」Wenger 补充道,「这可能导致少数群体或观点的代表性减少,甚至可能被抹去。」
大型科技公司正在采取一些措施,以减少普通网络用户看到的 AI 生成内容的数量。3 月份,谷歌宣布将调整其算法,把那些看起来是为搜索引擎而非人类搜索者设计的页面的优先级进行降低。然而,这一声明是在 404 Media 关于谷歌新闻推广 AI 生成文章的报道之后发布的。
《自然》杂志封面的这项研究强调,访问原始数据源并在递归训练的模型中仔细过滤数据,有助于保持模型的准确性。
该研究还建议,创建大型语言模型(LLM)的 AI 社区可以协调合作,追踪输入到模型中的信息来源。「否则,随着这种技术的广泛应用,如果无法获得在技术普及之前从互联网上爬取的数据或大量人类生成的数据,训练新的 LLM 版本可能会变得越来越困难」,研究团队总结道。




还没有评论,来说两句吧...