

今天凌晨,OpenAI 突然发布了 GPT-4o 的迷你版本 ——GPT-4o mini。这个模型替代了原来的 GPT-3.5,作为免费模型在 ChatGPT 上提供。其 API 价格也非常美丽,每百万输入 token 仅为 15 美分,每百万输出 token 60 美分, 比之前的 SOTA 模型便宜一个数量级,比 OpenAI 此前最便宜的 GPT-3.5 Turbo 还要便宜 60% 以上。
OpenAI CEO 山姆・奥特曼对此的形容是:通往智能的成本已经「too cheap to meter」。
与动辄上千亿参数的大模型相比,小模型的优势是显而易见的:它们不仅计算成本更低,训练和部署也更为便捷,可以满足计算资源受限、数据安全级别较高的各类场景。因此,在大笔投入大模型训练之余,像 OpenAI、谷歌等科技巨头也在积极训练好用的小模型。
其实,比 OpenAI 官宣 GPT-4o mini 早几个小时,被誉为「欧洲版 OpenAI」的 Mistral AI 也官宣了一个小模型 ——Mistral NeMo。

这个小模型由 Mistral AI 和英伟达联合打造,参数量为 120 亿(12B),上下文窗口为 128k。
Mistral AI 表示,Mistral NeMo 的推理能力、世界知识和编码准确性在同类产品中都是 SOTA 级别的。由于 Mistral NeMo 依赖于标准架构,因此易于使用,可在任何使用 Mistral 7B 的系统中成为替代品。
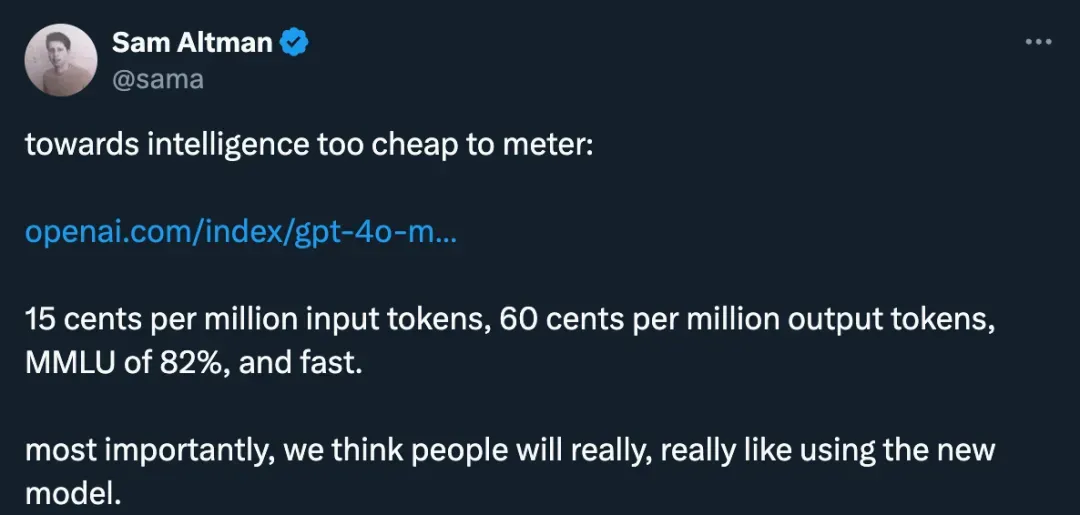
下表比较了 Mistral NeMo 基本模型与两个最新的开源预训练模型(Gemma 2 9B 和 Llama 3 8B)的准确性。(严格来讲,这个对比不太公平,毕竟Mistral NeMo 的参数量比另外两个都要大不少)
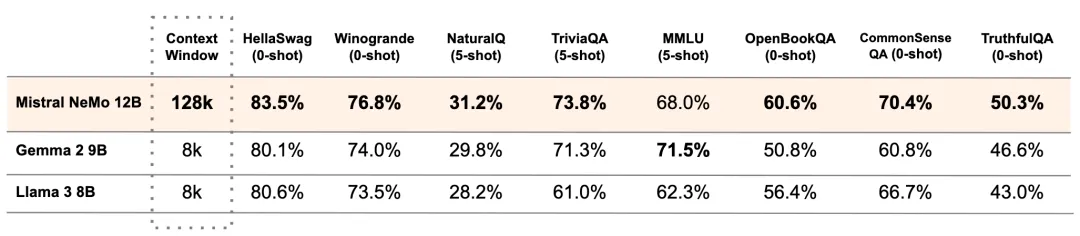
表 1:Mistral NeMo 基本模型与 Gemma 2 9B 和 Llama 3 8B 的性能比较。
他们在 Apache 2.0 许可证下发布了预训练的基本检查点和指令微调检查点,允许商用。Mistral NeMo 经过量化感知训练,可在不损失任何性能的情况下进行 FP8 推理。
面向大众的多语言模型
该模型专为全球多语言应用而设计。它受过函数调用训练,拥有一个大型上下文窗口,在英语、法语、德语、西班牙语、意大利语、葡萄牙语、中文、日语、韩语、阿拉伯语和印地语方面表现尤为突出。
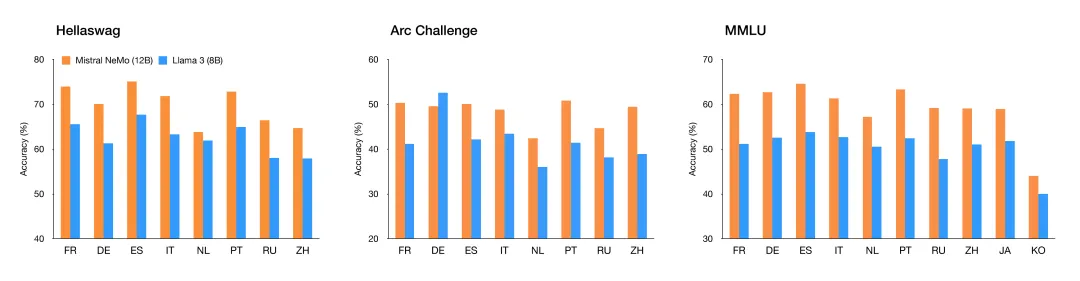
图 1:Mistral NeMo 在多语言基准测试中的表现。
Tekken:更高效的分词器
Mistral NeMo 使用基于 Tiktoken 的新分词器 Tekken,该分词器经过 100 多种语言的训练,能比以前 Mistral 模型中使用的 SentencePiece 分词器更有效地压缩自然语言文本和源代码。在压缩源代码、中文、意大利文、法文、德文、西班牙文和俄文时,它的效率要高出约 30%。在压缩韩文和阿拉伯文时,它的效率是原来的 2 倍和 3 倍。事实证明,与 Llama 3 分词器相比,Tekken 在压缩所有语言中约 85% 的文本方面更胜一筹。
图 2:Tekken 的压缩率。
指令微调
Mistral NeMO 经历了高级微调和对齐阶段。与 Mistral 7B 相比,它在遵循精确指令、推理、处理多轮对话和生成代码方面的能力大大提升。

表 2:Mistral NeMo 指令微调模型的准确率。使用 GPT4o 作为裁判进行的评估。
Mistral NeMo 基础模型和指令微调模型的权重都托管在 HuggingFace 上。
基础模型:https://huggingface.co/mistralai/Mistral-Nemo-Base-2407
指令微调模型:https://huggingface.co/mistralai/Mistral-Nemo-Instruct-2407
你现在就可以使用 mistral-inference 试用 Mistral NeMo,并使用 mistral-finetune 对其进行调整。
该模型被还打包在一个容器中,作为 NVIDIA NIM inference 微服务,可从 ai.nvidia.com 获取。
模型变小之后,小公司也能用 AI 赚钱了
在接受 Venturebeat 采访时,英伟达应用深度学习研究副总裁 Bryan Catanzaro 详细阐述了小型模型的优势。他说:「小型模型更容易获取和运行,可以有不同的商业模式,因为人们可以在家中自己的系统上运行它们。事实上,Mistral NeMo 可以在许多人已经拥有的 RTX GPU 上运行。」

这一进展发生在 AI 行业的关键时刻。虽然很多注意力都集中在拥有数千亿参数的庞大模型上,但人们对能够在本地商业硬件上运行的更高效模型越来越感兴趣。这种转变是由对数据隐私的担忧、对更低延迟的需求以及对更具成本效益的 AI 解决方案的渴望所驱动的。
Mistral-NeMo 128k 的上下文窗口是一个突出的功能,允许模型处理和理解比许多竞争对手更多的文本块。Catanzaro 说:「我们认为长上下文能力对许多应用来说可能很重要。如果无需进行微调,那模型会更容易部署。」
这种扩展的上下文窗口对于处理冗长文档、复杂分析或复杂编码任务的企业来说尤其有价值。它有可能消除频繁上下文刷新的需要,从而产生更加连贯一致的输出。
该模型的效率和本地部署能力可能会吸引在联网受限或有严格数据隐私要求的环境中运营的企业。然而,Catanzaro 澄清了该模型的预期使用场景。他说:「我会更多地考虑笔记本电脑和台式电脑,而不是智能手机。」
这一定位表明,虽然 Mistral-NeMo 使 AI 更接近个人业务用户,但它还没有达到移动部署的水平。
行业分析师认为,这次发布可能会显著扰乱 AI 软件市场。Mistral-NeMo 的推出代表了企业 AI 部署的潜在转变。通过提供一种可以在本地硬件上高效运行的模型,英伟达和 Mistral AI 正在解决阻碍许多企业广泛采用 AI 的担忧,如数据隐私、延迟以及与基于云的解决方案相关的高成本。
这一举措可能会使竞争环境更加公平,允许资源有限的小型企业利用以前只有拥有大量 IT 预算的大型公司才能获得的 AI 能力。然而,这一发展的真实影响将取决于模型在实际应用中的表现以及围绕它构建的工具和支持生态系统。
随着各行业的企业继续努力将 AI 整合到他们的运营中,像 Mistral-NeMo 这样的模型代表了向更高效、可部署的 AI 解决方案的转变。这是否会挑战更大、基于云的模型的主导地位还有待观察,但它无疑为 AI 在企业环境中的整合开辟了新的可能性。




还没有评论,来说两句吧...