

让现在最火的 SOTA 模型们(GPT-4o,Gemini-1.5,Sonnet-3,Sonnet-3.5)数一数两条线有几个交点,他们表现会比人类好吗?
答案很可能是否定的。
自 GPT-4V 推出以来,视觉语言模型 (VLMs) 让大模型的智能程度朝着我们想象中的人工智能水平跃升了一大步。
VLMs 既能看懂画面,又能用语言来描述看到的东西,并基于这些理解来执行复杂的任务。比如,给 VLM 模型发去一张餐桌的图片,再发一张菜单的图片,它就能从两张图中分别提取啤酒瓶的数量和菜单上的单价,算出这顿饭买啤酒花了多少钱。
VLMs 的进步如此之快,以至于让模型找出这张图中有没有一些不合常理的「抽象元素」,例如,让模型鉴定图中有没有一个人正在飞驰的出租车上熨衣服,成为了一种通行的测评方式。

然而,目前的基准测试集并不能很好地评估 VLMs 的视觉能力。以 MMMU 为例,其中有 42.9% 的问题不需要看图,就能解决,也就是说,许多答案可以仅通过文本问题和选项推断出来。其次,现在 VLM 展示出的能力,很大程度上是「背记」大规模互联网数据的结果。这导致了 VLMs 在测试集中的得分很高,但这并不代表这个判断成立:VLM 可以像人类一样感知图像吗?
为了得到这个问题的答案,来自奥本大学和阿尔伯塔大学的研究者决定给 VLMs「测测视力」。从验光师的「视力测试」处得到了启发,他们让:GPT-4o、Gemini-1.5 Pro 、Claude-3 Sonnet 和 Claude-3.5 Sonnet 这四款顶级 VLM 做了一套「视力测试题」。

论文标题:Vision language models are blind
论文链接:https://arxiv.org/pdf/2407.06581
项目链接:https://vlmsareblind.github.io/
这套题很简单,例如,数两条线有几个交点,识别是哪个字母被红圈标出来了,几乎不需要任何世界知识。测试结果令人震惊,VLMs 实际上都「近视」,图片的细节在它们看来实际是模糊的。
VLM 瞎不瞎?七大任务,一测便知
为了避免 VLMs 从互联网数据集中直接「抄答案」,论文作者设计了一套全新的「视力测试」。论文作者选择让 VLMs 判断空间中几何图形之间的关系,例如两个图形是否相交。因为这些图案在白色画布上的空间信息,通常无法用自然语言描述。
人类在处理这些信息时,将通过「视觉大脑」感知。但对于 VLMs 来说,它们所依靠的是在模型的初期阶段将图像特征和文本特征结合起来,即将视觉编码器集成到大型语言模型中,这本质上是一个没有眼睛的知识大脑。
初步实验表明,VLMs 在面对人类视力测试,比如我们每个人都测过的颠来倒去的「E」视力表等等,它们的表现已经非常惊艳。
测试与结果
第一关:数一数线条之间有几个交点?
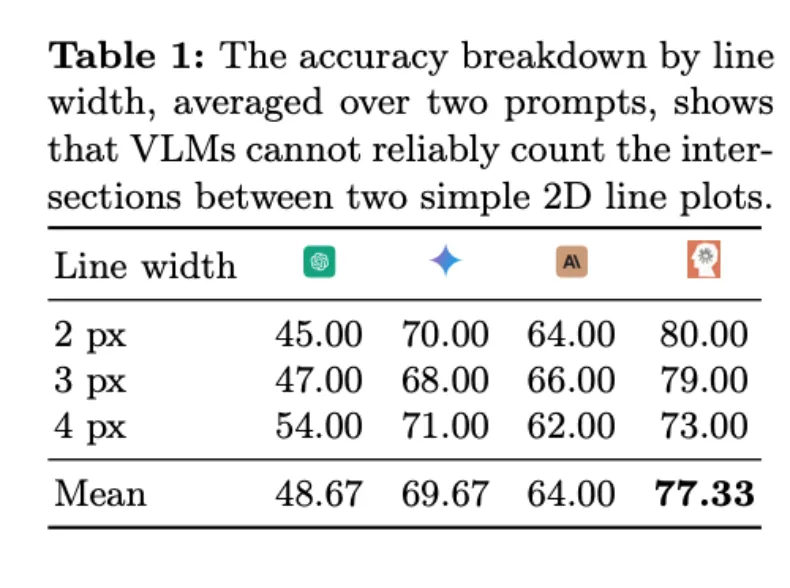
论文作者在白色背景上创建了 150 幅含有两条线段的图像。这些线段的 x 坐标固定并等间距分布,而 y 坐标则是随机生成的。两条线段之间的交点只有 0 个、1 个、2 个三种情况。

如图 5 所示,在两版提示词和三版线段粗细不同的测试中,所有 VLMs 在这个简单任务上表现都不佳。

拥有最佳准确率的 Sonnet-3.5 也仅为 77.33%(见表 1)。
更具体地说,当两条线之间的距离缩小时,VLMs 的表现往往更差(见下方图 6)。由于每个线图由三个关键点组成,两条线之间的距离计算为三个对应点对的平均距离。
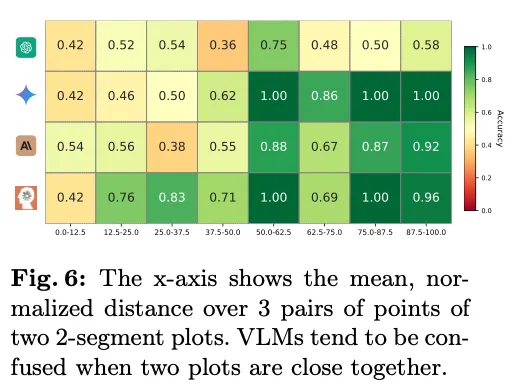
该结果与 VLMs 在 ChartQA 上的高准确率形成鲜明对比,这表明 VLMs 能够识别线图的整体趋势,但无法「放大」以看到类似于「哪些线条相交了」这种细节。
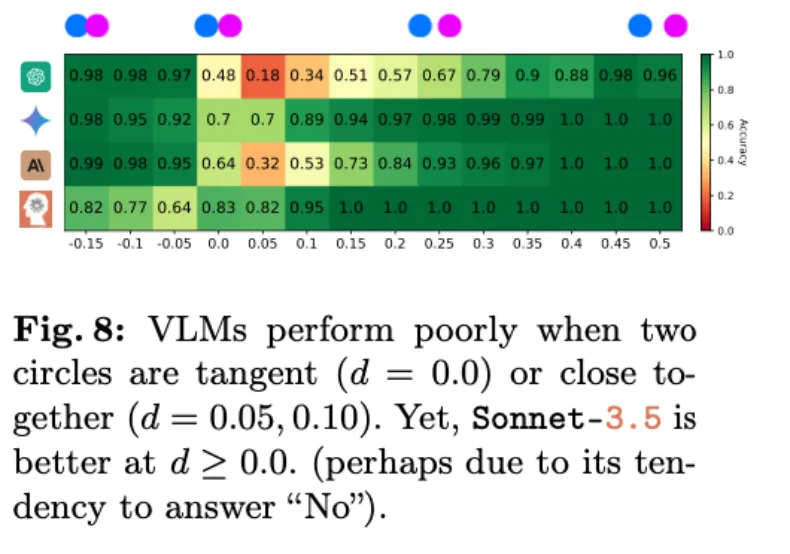
第二关:判断两个圆之间的位置关系
如图所示,论文作者在一个给定大小的画布上,随机生成两个大小一致的圆。两个圆的位置关系只有三种情况:相交、相切和相离。
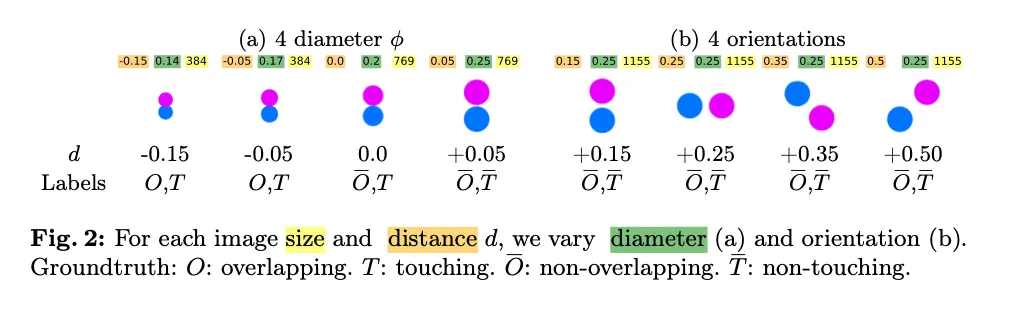
令人惊讶的是,在这个对人类来说直观可见,一眼就能看出答案的的任务中,没有一个 VLM 能够完美地给出答案(见图 7)。

准确率最佳(92.78%)的模型是 Gemini-1.5(见表 2)。
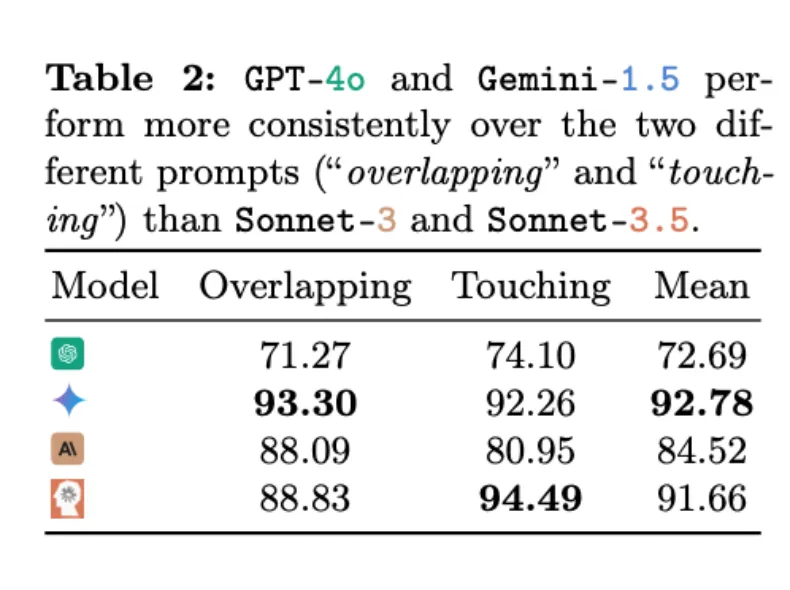
在实验中,有一种情况频繁出现:当两个圆靠得很近时,VLMs 往往表现不佳,但会做出有根据的推测。如下图所示,Sonnet-3.5 通常保守地回答「否」。

如图 8 所示,即使当两个圆之间的距离相差得很远,有一个半径(d = 0.5)这么宽时,准确率最差的 GPT-4o 也做不到 100% 准确。
也就是说,VLM 的视觉似乎不够清晰,无法看到两个圆之间的细小间隙或交点。
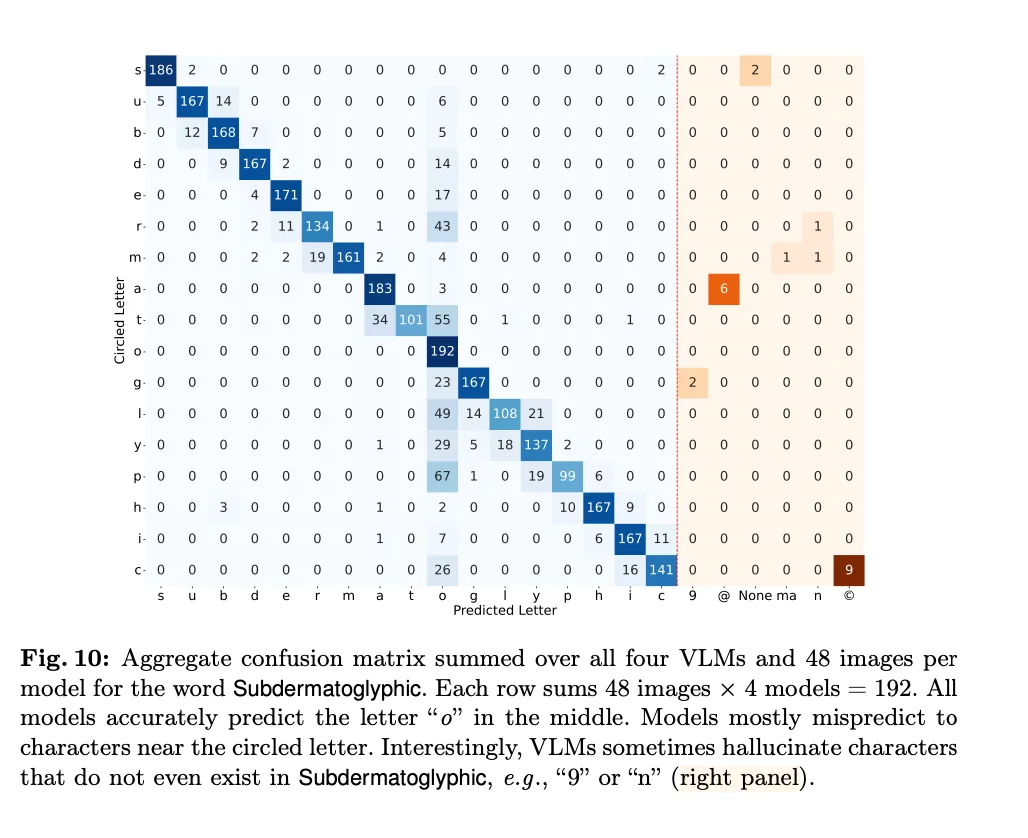
第三关:有几个字母被红圈圈起来了?
由于一个单词间字母之间的间隔很小,论文作者们假设:如果 VLMs「近视」,那么它们是没办法识别出被红圈圈出的字母的。
因此,他们选择了「Acknowledgement」、「Subdermatoglyphic」和「tHyUiKaRbNqWeOpXcZvM」这样的字符串。随机生成红圈圈出字符串中的某个字母,作为测试。

测试结果说明,被测模型在这一关的表现都很差(见图 9 和表 3)。


例如,当字母被红圈轻微遮挡时,视觉语言模型往往会出错。它们经常混淆红圈旁边的字母。有时模型会产生幻觉,例如,尽管能够准确拼写单词,但会给单词中添加(例如,「9」,「n」,「©」)等乱码。

除了 GPT-4o 之外,所有模型在单词上的表现都略好于随机字符串,这表明知道单词的拼写可能有助于视觉语言模型做出判断,从而略微提高准确性。
Gemini-1.5 和 Sonnet-3.5 是排名前二的模型,准确率分别为 92.81% 和 89.22%,并且比 GPT-4o 和 Sonnet-3 的表现近乎高出近 20%。
第四关和第五关:重叠的图形有几个?有几个「套娃」正方形?
假设 VLMs「近视」,那么它们可能无法清晰地看到类似于「奥运五环」这样的图案,每两个圆圈之间的交叉点。为此,论文作者随机生成了 60 组类似于「奥运五环」的图案,让 VLMs 数一数它们重叠的图形有几个。他们也生成了五边形版的「奥运五环」进一步测试。

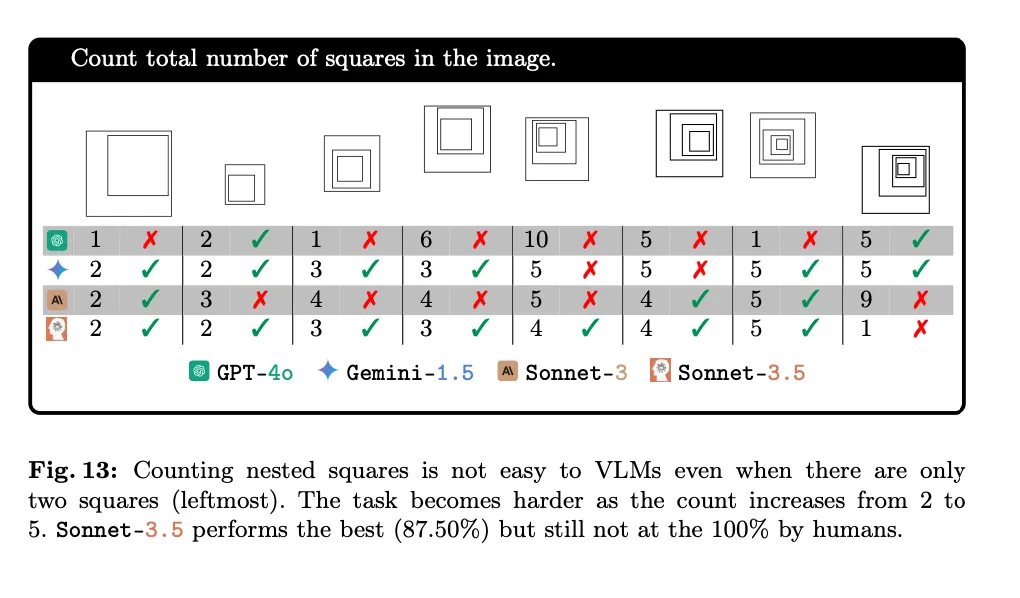
由于 VLMs 计算相交圆圈的数量时表现不佳,论文作者进一步测试了当图案的边缘不相交,每个形状完全嵌套在另一个形状内部的情况。他们用 2-5 正方形生成了「套娃」式的图案,并让 VLMs 计算图像中的正方形总数。
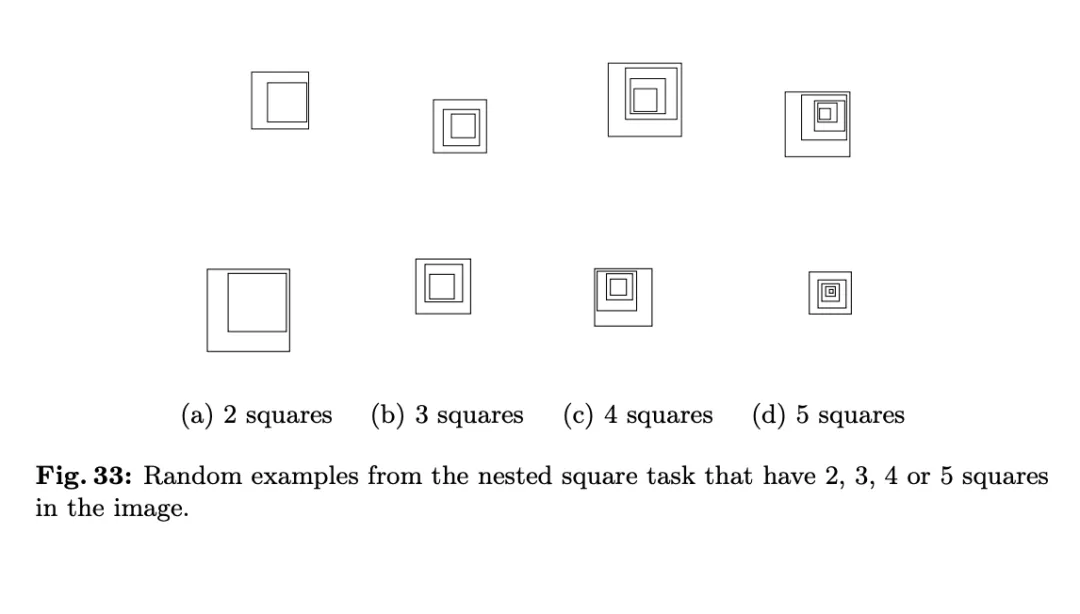
从下表中鲜红的叉号不难看出,这两关对于 VLMs 来说,也是难以逾越的障碍。

在嵌套正方形的测试中,各个模型的准确率差异很大:GPT-4o(准确率 48.33%)和 Sonnet-3(准确率 55.00%)这两种模型至少比 Gemini-1.5(准确率 80.00%)和 Sonnet-3.5(准确率 87.50%)低 30 个百分点。
这种差距在模型计数重叠的圆形和五边形时则会更大,不过 Sonnet-3.5 的表现要比其他模型好上几倍。如下表所示,当图像为五边形时,Sonnet-3.5 以 75.83% 的准确率远超 Gemini-1.5 的 9.16%。
令人惊讶的是,被测的四个模型在数 5 个圆环时都达到了 100% 的准确率,但仅仅额外添加一个圆环就足以使准确率大幅下降到接近零的水平。
然而,在计算五边形时,所有 VLM(除 Sonnet-3.5 外)即使在计算 5 个五边形时也表现不佳。总体来看,计算 6 到 9 个形状(包括圆和五边形)对所有模型来说都是困难的。
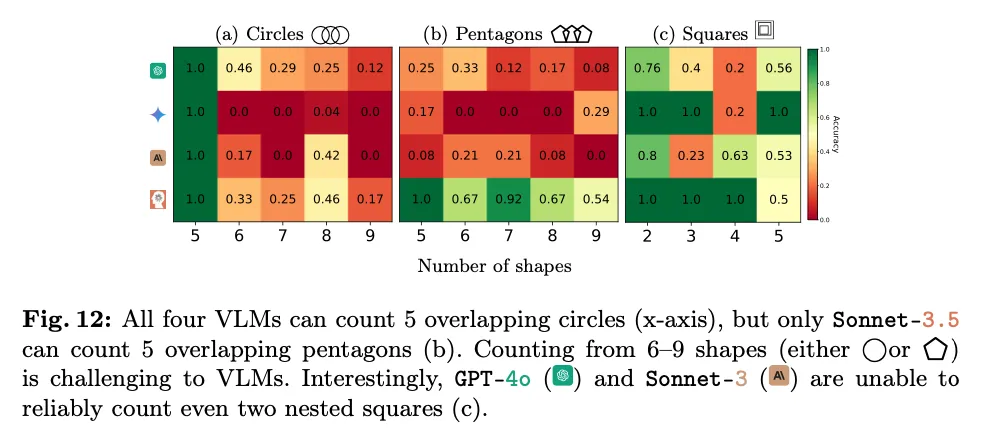
这表明,VLM 存在偏见,它们更倾向于输出著名的「奥运五环」作为结果。例如,无论实际圆的数量是多少,Gemini-1.5 都会在 98.95% 的试验里将结果预测为「5」(见表 5)。对于其他模型,这种圆环预测错误出现的频率也远高于五边形的情况。

除了数量外,VLM 在形状的颜色上也有不同的「偏好」。
GPT-4o 在彩色形状上的表现优于纯黑的形状,而 Sonnet-3.5 随着图像尺寸的增加预测的表现越来越好。然而,当研究人员改变颜色和图像分辨率时,其他模型的准确率仅略有变化。
值得注意的是,在计算嵌套正方形的任务中,即使正方形的数量只有 2-3 个,GPT-4o 和 Sonnet-3 依然很难计算。当正方形的数量增加到四个和五个时,所有模型都远未达到 100% 的准确率。这表明,即使形状的边缘不相交,VLM 也很难准确地提取目标形状。
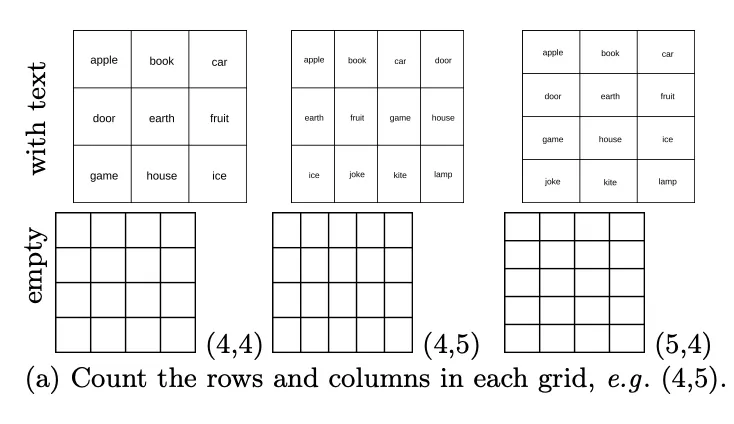
第六关:数一数表格有几行?有几列?
虽然 VLMs 在重叠或嵌套图形时遇到了困难,但它们眼中的平铺图案又是怎样的呢?在基础测试集中,特别是包含许多含有表格任务的 DocVQA,被测模型的准确率都≥90%。论文作者随机生成了 444 个行数列数各异的表格,让 VLMs 数一数表格有几行?有几列?
结果显示,虽然在基础数据集中拿到了高分,但如下图所示,VLM 在计数空表格中的行和列也表现不佳。
具体来说,它们通常会存在 1-2 格的偏差。如下图所示,GPT-4o 把 4×5 的网格认成了 4×4,Gemini-1.5 则认成了 5×5。

这表明,虽然 VLMs 可以从表格中提取重要内容以回答 DocVQA 中的表格相关问题,但无法清晰地逐格识别表格。
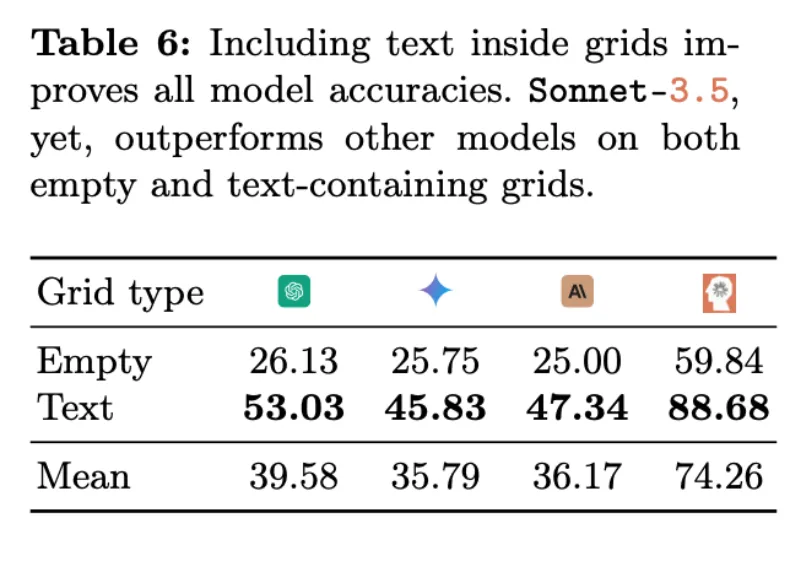
这可能是因为文档中的表格大多是非空的,而 VLM 不习惯空表格。有趣的是,在研究人员通过尝试在每个单元格中添加一个单词来简化任务后,观察到所有 VLM 的准确率显著提高,例如,GPT-4o 从 26.13% 提高到了 53.03%(见表 6)。然而,这种情况中,被测模型的表现依旧不完美。如图 15a 和 b 所示,表现最好的模型(Sonnet-3.5)在包含文本的网格中表现为 88.68%,而在空网格中表现为 59.84%。
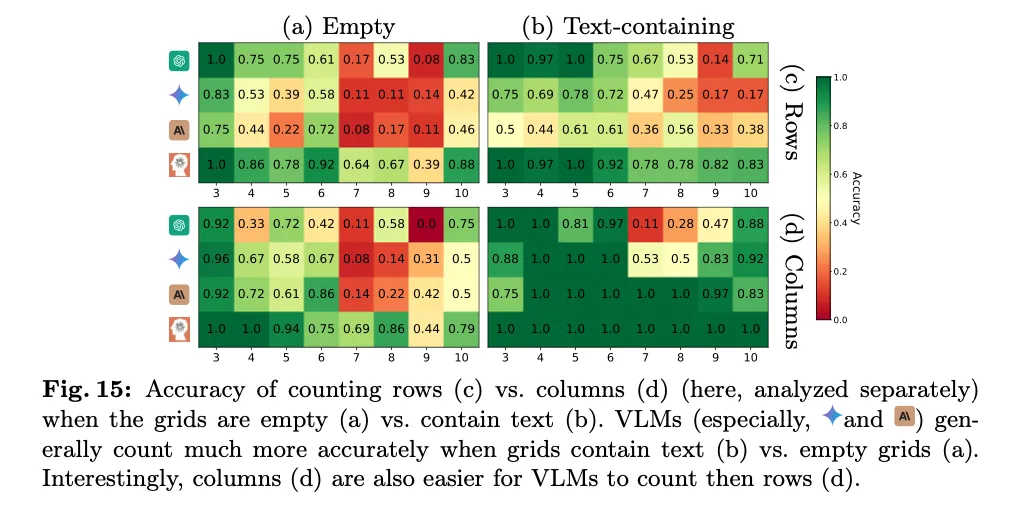
而大多数模型(Gemini-1.5、Sonnet-3 和 Sonnet-3.5)在计算列数方面的表现始终优于计算行数(见图 15c 和 d)。
第七关:从出发点到目的地,有几条地铁直达线路?
这项测试检测的是 VLMs 跟随路径的能力,这对于模型解读地图、图表以及能否理解用户在输入的图片中添加的箭头等标注至关重要。为此,论文作者随机生成了 180 幅地铁线路图,每张图有四个固定的站点。他们要求 VLMs 计算两个站点之间有多少条单色的路径。
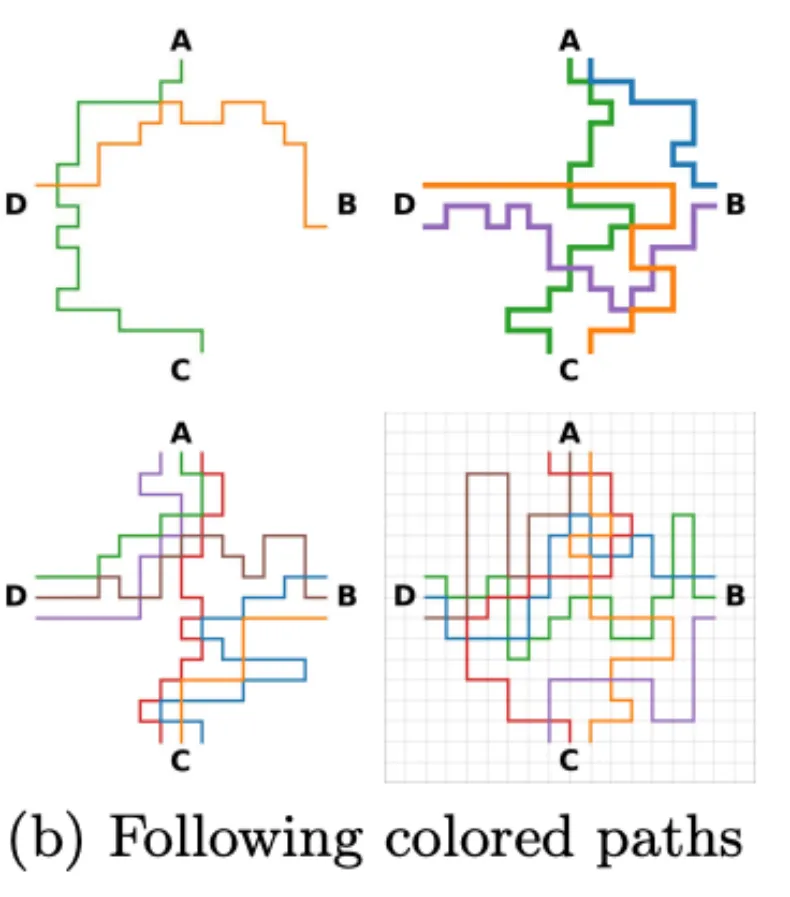
测试结果令人震惊,即使把两个站点之间的路径简化到只有一条,所有模型也无法达到 100% 的准确率。如表 7 所示,表现最好的模型是 Sonnet-3.5,准确率为 95%;最差的模型是 Sonnet-3,准确率为 23.75%。
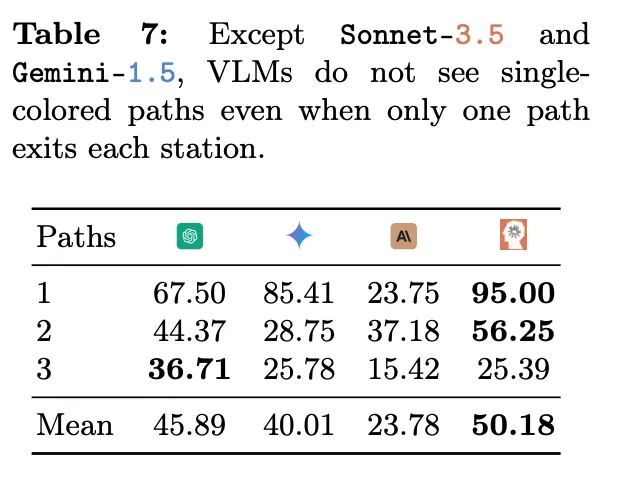
从下图中不难看出,VLM 的预测通常会有 1 到 3 条路径的偏差。随着地图复杂度从 1 条路径增加到 3 条路径,大多数 VLM 的表现都变得更差。

面对当今主流 VLM 在图像识别上表现极差这一「无情事实」,众多网友先是抛开了自己「AI 辩护律师」的身份,留下了很多较为悲观的评论。
一位网友表示:「SOTA 模型们(GPT-4o,Gemini-1.5 Pro,Sonnet-3,Sonnet-3.5)表现得如此糟糕真是令人尴尬,而这些模型居然在宣传时还声称:它们可以理解图像?例如它们可以用于帮助盲人或辅导儿童几何学!

在悲观阵营的另一方,一位网友认为这些糟糕的结果可以通过训练和微调轻松解决。只需生成大约 100,000 个示例,并用真实数据进行训练,这样问题就解决了。

不过,无论是「AI 辩护者」还是「AI 悲观者」都默认了一个事实:VLM 在图像测试中,仍然存在极难调和的事实性缺陷。
论文作者也收到了对更多这个测试是否科学的质疑。

有网友认为,这篇论文的测试并不能说明 VLMs「近视」。首先近视的人看细节并不模糊,「看细节模糊」是远视的症状。其次,看不见细节与不能计算交点的数量是两回事。计算空白网格的行和列的数量的准确率,不会因为分辨率的提高而提高,而提高图像的分辨率对于理解这个任务并没有帮助。此外,提高图像分辨率对于理解这个任务中的重叠线条或交叉点并不会产生显著影响。
实际上,这些视觉语言模型(VLMs)在处理这类任务时所面临的挑战,可能更多地与它们的推理能力和对图像内容的解释方式有关,而不仅仅是视觉分辨率的问题。换句话说,即使图像的每个细节都清晰可见,如果模型缺乏正确的推理逻辑或对视觉信息的深入理解,它们仍然可能无法准确地完成这些任务。因此,这项研究可能需要更深入地探讨 VLMs 在视觉理解和推理方面的能力,而不仅仅是它们的图像处理能力。
还有网友认为,如果人类的视觉经过卷积处理,那么人类自身也会在判断线条交点的测试中遇到困难。
更多信息,请参考原论文。




还没有评论,来说两句吧...