

大语言模型的Scaling Law被一些人视为「金科玉律」,但另一些人却不以为意。前阵子,香港大学马毅教授就公开宣称,「如果相信只靠Scaling Law就能实现AGI,你该改行了」。
确实有很多模型不是单纯靠资源的堆砌,而是凭借创新能力脱颖而出。验证了一条不同于Scaling Law的道路——少即是多。
xLAM-1B就是如此,只有10亿参数,但是在功能调用任务中表现优于更大规模的模型,包括OpenAI的GPT-3.5 Turbo和Anthropic的Claude-3 Haiku。

它也因此被称为「Tiny Giant」——小巨人!
凭借远超预期的卓越性能,这个小模型或许会改变端侧AI的格局。

西方将这种以弱胜强的故事称之为「David-versus-Goliath」(大卫迎战歌利亚),这源于一个圣经故事——大卫与巨人歌利亚作战时还是个孩子,他不像歌利亚那样穿着盔甲,他捡了一块石头,放在投石器里。把石头甩出去,击中歌利亚的额头,击倒了这个巨人。
科技媒体Venturebeat在报道这个小模型时,就将之比喻为人工智能领域的「大卫迎战歌利亚」时刻。
我们最关心的一点是,xLAM-1B是如何做到的?
简言之,这得益于在数据处理上的创新方法。其背后团队开发了APIGen,这是一套自动化流程,可以生成高质量、多样化且可验证的数据集,用于训练AI模型在函数调用任务中的表现。

论文地址:https://arxiv.org/pdf/2406.18518
小而强大:高效AI的力量
xLAM-1B最令人欣喜的在于,它不占地儿。因为模型规模小,所以适合设备上的应用。这对企业人工智能的影响是巨大的,它有可能使AI助手功能更强大、反应更灵敏,并且能在计算资源有限的智能手机或其他设备上本地运行。
训练数据的质量和多样性是支撑xLAM-1B强大性能的关键。APIGen自动数据生成流水线利用21个不同类别的3673个可执行API,对每个数据点进行了严格的三阶段验证:格式检查、实际函数执行和语义验证。
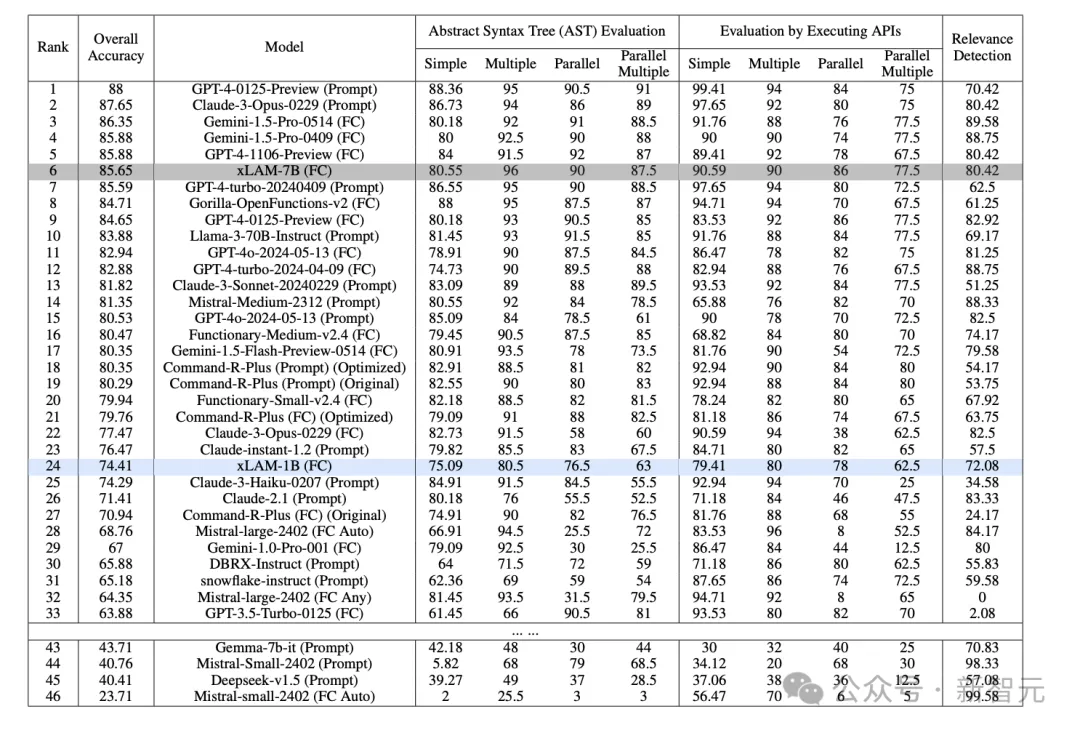
各种AI模型在不同评估指标下的性能对比图。GPT-4-0125-Preview在总体准确性方面遥遥领先,而xLAM-7B等较小的模型在特定任务中表现出了竞争力,这对大模型总是表现更好的说法提出了挑战
这种方法代表了人工智能发展战略的重大转变。
虽然许多公司都在竞相建立越来越大的模型,但xLAM-1B所使用的方法表明,更智能的数据处理可以带来更高效、更有效的人工智能系统。
通过关注数据质量而非模型大小,xLAM-1B提供了一个很好的例子,它可以用比竞争对手少得多的参数执行复杂的任务。
颠覆AI现状:从LLM到SLM
这一突破的潜在影响绝不仅限于xLAM-1B这个模型的推出。
通过证明更小、更高效的模型可以与更大的模型竞争,xLAM-1B正在挑战人工智能行业的主流观点,作为小语言模型(SLM)的新军,和一统江湖的大语言模型(LLM)开战。
科技公司一直在争相建立最大的大语言模型。例如,今年4月,Meta公司发布了拥有4000亿参数的Llama 3,它所包含的参数数量是2022年OpenAI最初的ChatGPT模型的两倍。
尽管尚未得到证实,但GPT-4估计拥有约1.8万亿个参数。
不过,在过去几个月里,包括苹果和微软在内的一些最大的科技公司都推出了小语言模型。
这些模型的大小仅为LLM对应模型的一小部分,但在许多基准测试中,它们在文本生成方面可以与LLM相媲美,甚至更胜一筹。
6月10日,在苹果公司的全球开发者大会上,发布了拥有约30亿参数的苹果智能模型。
4月底,微软发布了其Phi-3 SLM系列,拥有38亿到140亿个参数。
在一系列测试中,微软最小的模型Phi-3-mini与OpenAI的GPT-3.5(1750亿个参数)不相上下,其表现也优于谷歌的Gemma(70亿个参数)。
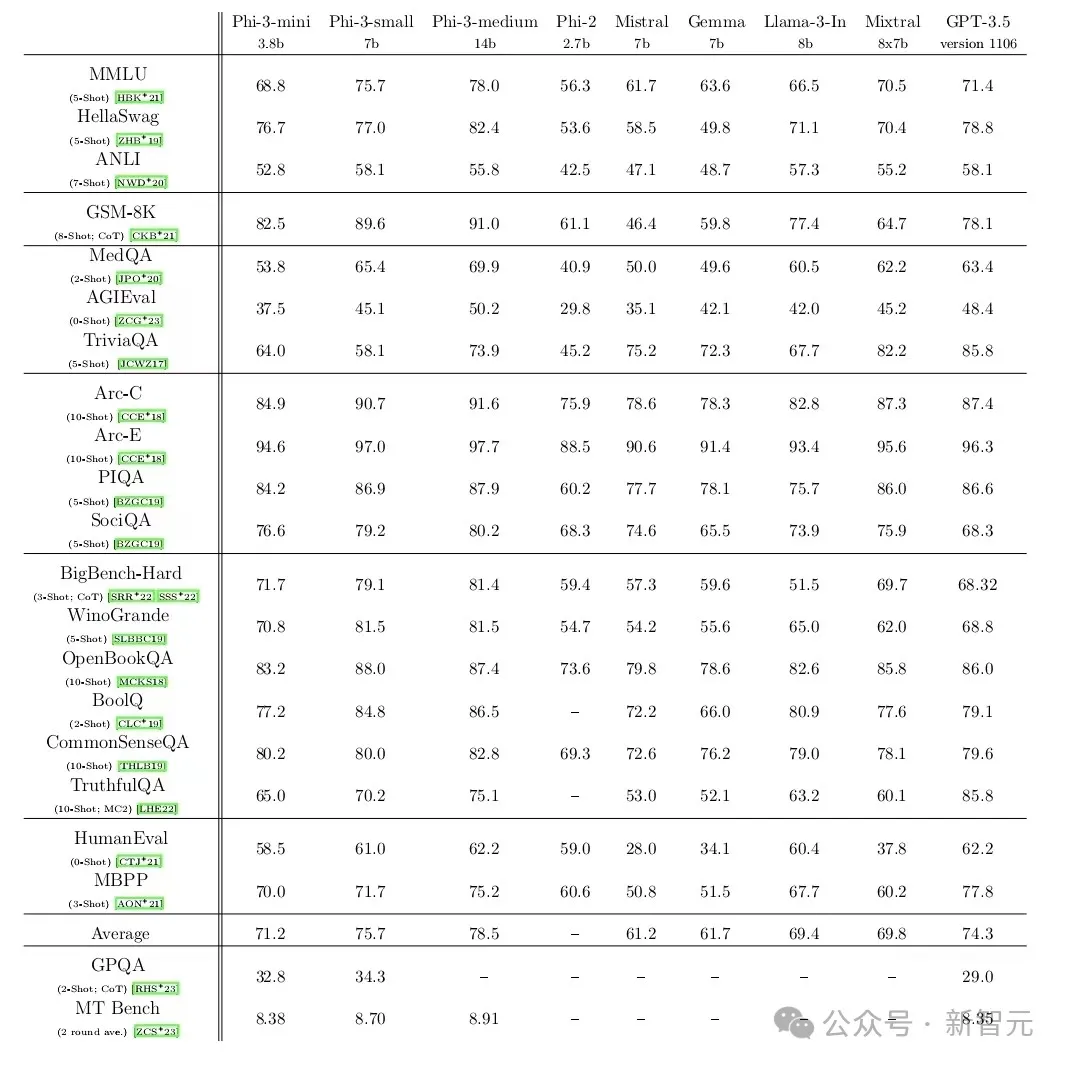
测试通过向模型提出有关数学、哲学、法律等方面的问题,评估了模型对语言的理解能力。
更有趣的是,拥有70亿个参数的微软Phi-3-small在许多基准测试中的表现都明显优于GPT-3.5。
波士顿东北大学研究语言模型Aaron Müller并不惊讶SLM在某些功能上可以与LLM相提并论。
Müller说,「这是因为一味增加参数数量并不是提高模型性能的唯一方法,在更高质量的数据上进行训练也能产生类似的结果。」
例如,微软的Phi模型是在经过微调的「教科书质量」数据上训练出来的,这些数据的风格更加一致,比LLM通常依赖的来自互联网的高度多样化文本更容易学习。
同样,苹果公司也在高质量、更复杂的数据集上训练SLM。
Müller表示,更重要的是,SLM可以使语言模型的使用平民化。
迄今为止,人工智能的开发一直集中在几家有能力部署高端基础设施的大公司手中,而其他规模较小的公司和实验室则不得不支付高昂的费用来获得授权。
由于SLM可以在价格更低廉的硬件上轻松训练,因此资源有限的人更容易获得SLM。
SLM的兴起正值LLM之间的性能差距迅速缩小,科技公司希望能在Scaling Law之外,探索其他性能升级途径。
在4月份的一次活动中,OpenAI 的首席执行官Altman表示,他相信我们正处于大模型时代的末期。「我们将以其他方式让模型变得更好。」
也就是说,经过精心策划的SLM向构建可解释性人工智能更近了一步。
对于像苏黎世联邦理工学院计算机科学研究员Alex Warstadt这样的研究人员来说,SLM还能为一个长期存在的科学问题提供新的见解:儿童是如何用很少的文字数据就学会语言和思维的。
Warstadt和包括东北大学Müller在内的一批研究人员一起组织了BabyLM挑战赛,参赛者要在小数据上优化语言模型训练。
SLM不仅有可能揭开人类认知的新秘密,还有助于改进生成式人工智能。
在儿童13岁时,他们已经接触了约1亿个单词,在语言方面比聊天机器人更胜一筹,但他们只能获得0.01%的数据。
Warstadt说,虽然没人知道是什么让人类如此高效,但「在小规模上进行高效的类人学习,当扩展到LLM规模时,可能会带来巨大的改进」。
重塑AI的未来:从云到设备
xLAM-1B展现出的端侧AI的发展潜力,很可能标志着人工智能领域的重大转变——挑战「模型越大越好」的观念,让人工智能在消耗有限资源的条件下也能持续生长。
目前,由于所涉及模型的规模和复杂性,许多先进的人工智能功能都依赖于云计算。
如果像xLAM-1B这样的较小模型也能提供类似的功能,就能让更强大的人工智能助手直接在用户的设备上运行,从而提高响应速度,并解决与基于云的人工智能相关的隐私问题。
随着边缘计算和物联网设备的激增,对更强大的设备上人工智能功能的需求也将激增。
xLAM-1B的成功可能会催生新一轮的人工智能开发浪潮,其重点是创建为特定任务量身定制的超高效模型,而不是「样样通」的庞然大物。
这可能会带来一个更加分布式的人工智能生态系统,在这个生态系统中,专业模型在设备网络中协同工作,可能会提供更强大、反应更快、更能保护隐私的人工智能服务。
这一发展还能使人工智能能力民主化,让较小的公司和开发人员无需大量计算资源就能创建复杂的人工智能应用。
此外,它还可以减少人工智能碳足迹,因为较小的模型在训练和运行时所需的能源要少得多。
xLAM-1B给业界带来的冲击有很多,但有一点是显而易见的:在人工智能的世界里,大卫刚刚证明了他不仅可以与歌利亚竞争,还有可能将其淘汰。人工智能的未来可能不在被巨头所操控的云端,而是在你自己手中。




还没有评论,来说两句吧...