

本文由 HMI Lab 完成。HMI Lab依托北京大学视频与视觉技术国家工程研究中心和多媒体信息处理全国重点实验室两大平台,长期从事机器学习、多模态学习和具身智能方向的研究。本工作第一作者为刘家铭博士,研究方向为面向开放世界的多模态具身大模型与持续性学习技术。本工作第二作者为刘梦真,研究方向为视觉基础模型与机器人操纵。指导老师为仉尚航,北京大学计算机学院研究员、博士生导师、博雅青年学者。从事多模态大模型与具身智能研究,取得了一系列重要研究成果,在人工智能顶级期刊和会议上发表论文 80 余篇,谷歌引用 9700 余次。荣获世界人工智能顶会 AAAI 最佳论文奖,位列世界最大学术源代码仓库 Trending Research 第一位。
为了赋予机器人端到端的推理和操纵能力,本文创新性地将视觉编码器与高效的状态空间语言模型集成,构建了全新的 RoboMamba 多模态大模型,使其具备视觉常识任务和机器人相关任务的推理能力,并都取得了先进的性能表现。同时,本文发现当 RoboMamba 具备强大的推理能力后,我们可以通过极低的训练成本使得 RoboMamba 掌握多种操纵位姿预测能力。

论文:RoboMamba: Multimodal State Space Model for Efficient Robot Reasoning and Manipulation
论文链接:https://arxiv.org/abs/2406.04339
项目主页:https://sites.google.com/view/robomamba-web
Github:https://github.com/lmzpai/roboMamba
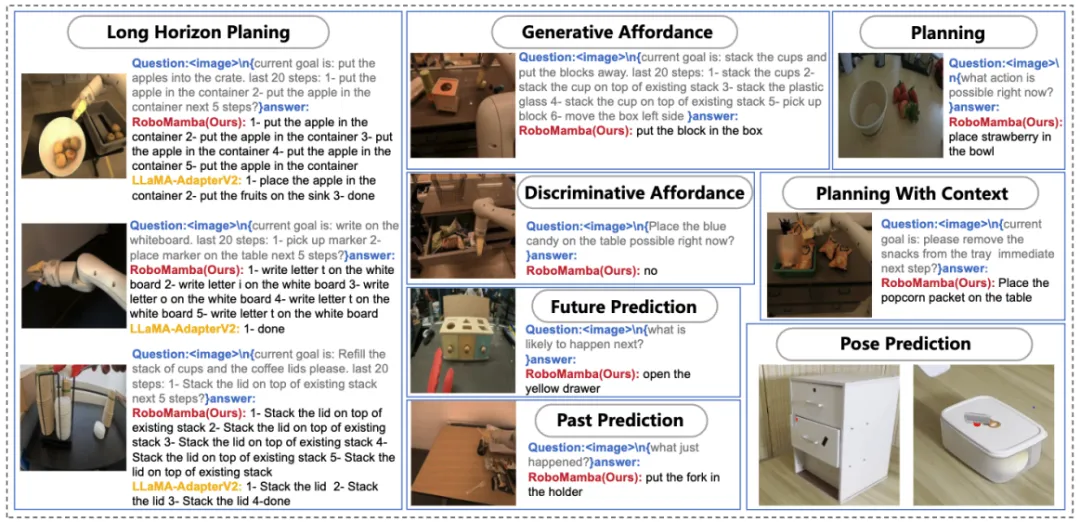
图 1. RoboMamba 具备的机器人相关能力,其中包括任务规划、提示性任务规划、长程任务规划、可操纵性判断、可操纵性生成、未来与过去预测、末端执行器位姿预测等。
摘要
机器人操纵的一个基本目标是使模型能够理解视觉场景并执行动作。尽管现有的机器人多模态大模型(MLLM)可以处理一系列基本任务,但它们仍然面临两个方面的挑战:1) 处理复杂任务的推理能力不足;2) MLLM 微调和推理的计算成本较高。最近提出的状态空间模型(SSM),即 Mamba,其具备线性推理复杂度同时在序列建模中展示了令人期待的能力。受此启发,我们推出了端到端机器人 MLLM—RoboMamba,它利用 Mamba 模型提供机器人推理和行动能力,同时保持高效的微调和推理能力。
具体来说,我们首先将视觉编码器与 Mamba 集成在一起,通过共同训练将视觉数据与语言嵌入对齐,使我们的模型具有视觉常识和与机器人相关的推理能力。为了进一步增强 RoboMamba 的操纵位姿预测能力,我们探索了一种仅使用简单 Policy Head 的高效微调策略。我们发现,一旦 RoboMamba 拥有足够的推理能力,它可以通过极少的微调参数(模型的 0.1%)和微调时间(20 分钟)来掌握多种操作技能。在实验中,RoboMamba 在通用和机器人评估基准上展示了出色的推理能力,如图 2 所示。同时,我们的模型在模拟和现实世界实验中展示了令人印象深刻的操纵位姿预测能力,其推理速度比现有的机器人 MLLMs 快 7 倍。
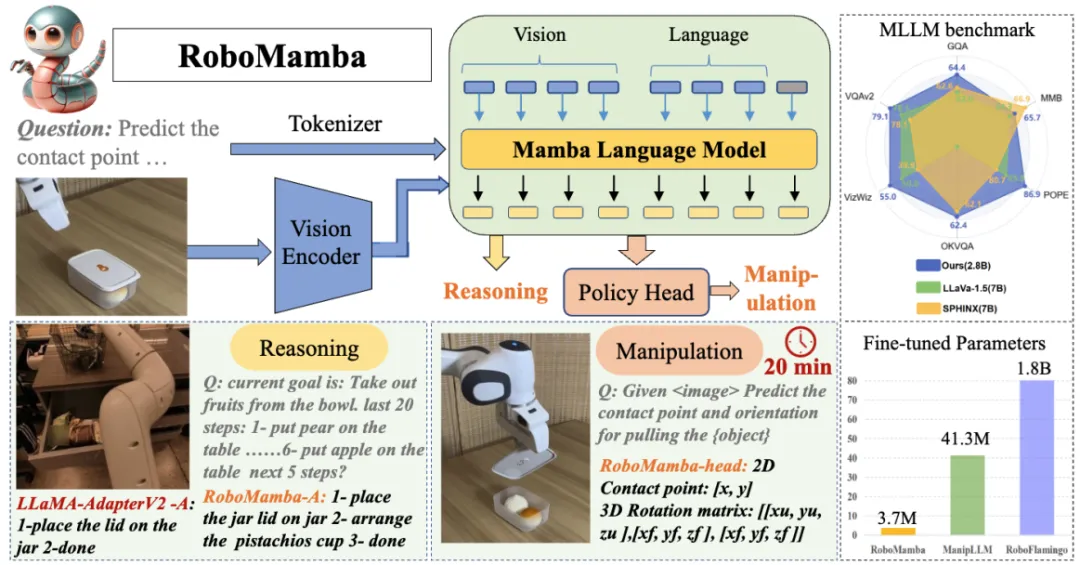
图 2. 概述:Robomamba 是一种高效的机器人多模态大模型,同时具备强大的推理和操作能力。RoboMamba-2.8B 在通用 MLLM 基准上实现了与其他 7B MLLM 可竞争的推理性能,同时在机器人任务中展示了长程推理能力。随后,我们引入了一种极其高效的微调策略,使 RoboMamba 具备操纵位姿预测能力,只需 20 分钟即可微调一个简单的策略头。
本文主要贡献总结如下:
我们创新地将视觉编码器与高效的 Mamba 语言模型集成,构建了全新的端到端机器人多模态大模型,RoboMamba,其具备视觉常识和机器人相关的全面推理能力。
为了使 RoboMamba 具备末端执行器操纵位姿预测能力,我们探索了一种使用简单 Policy Head 的高效微调策略。我们发现,一旦 RoboMamba 达到足够的推理能力,它可以以极低的成本掌握操纵位姿预测技能。
在我们的大量实验中,RoboMamba 在通用和机器人推理评估基准上表现出色,并在模拟器和真实世界实验中展示了令人印象深刻的位姿预测结果。
研究背景
数据的 scaling up 显著推动了大语言模型(LLMs)研究的发展,展示了在自然语言处理(NLP)中推理和泛化能力的显著进步。为了理解多模态信息,多模态大语言模型(MLLMs)应运而生,赋予 LLMs 视觉指令跟随和场景理解的能力。受 MLLMs 在通用环境中强大能力的启发,近期研究旨在将 MLLMs 应用于机器人操作领域。一些研究工作使机器人能够理解自然语言和视觉场景,自动生成任务计划。另一些研究工作则是利用 MLLMs 的固有能力,使其具备预测操作位姿的能力。
机器人操作涉及在动态环境中与物体交互,需要类人推理能力以理解场景的语义信息,以及强大的操纵位姿预测能力。虽然现有基于机器人 MLLM 可以处理一系列基础任务,但它们在两个方面仍然面临挑战。
1)首先,预训练的 MLLMs 在机器人场景中的推理能力被发现是不足的。正如图 2
所示,当微调后的机器人 MLLMs 遇到复杂推理任务时,这种缺陷会带来挑战。
2)其次,由于现有 MLLM 注意力机制的计算复杂度较高,微调 MLLMs 并使用它们生成机器人操作动作会产生更高的计算成本。
为了平衡推理能力和效率,NLP 领域出现了几项研究。尤其是,Mamba 引入了创新的选择性状态空间模型(SSM),在保持线性复杂度的同时,促进了上下文感知的推理。
受此启发,我们提出一个问题:“我们能否开发出一种高效的机器人 MLLM,既具备强大的推理能力,又能以非常经济的方式获得机器人操作技能?”
RoboMamba 方法
1. 背景知识
问题陈述
对于机器人视觉推理,我们的 RoboMamba 基于图像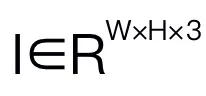 和语言问题
和语言问题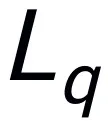 生成语言答案
生成语言答案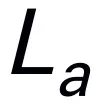 ,表示为
,表示为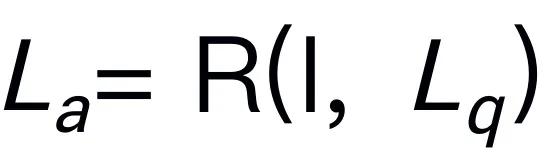 。推理答案通常包含单独的子任务
。推理答案通常包含单独的子任务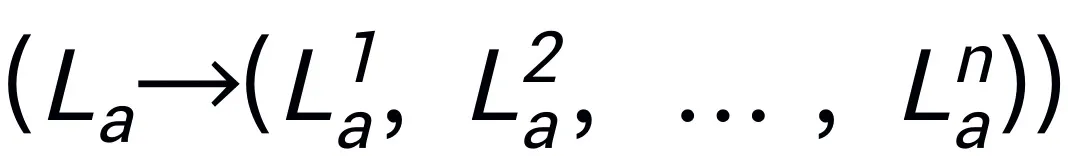 对于一个问题
对于一个问题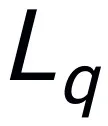 。例如,当面对一个计划问题,如 “如何收拾桌子?”,反应通常包括 “第一步:捡起物体” 和 “第二步:把物体放入盒子” 等步骤。对于动作预测,我们利用一个高效简单的策略头 π 来预测动作
。例如,当面对一个计划问题,如 “如何收拾桌子?”,反应通常包括 “第一步:捡起物体” 和 “第二步:把物体放入盒子” 等步骤。对于动作预测,我们利用一个高效简单的策略头 π 来预测动作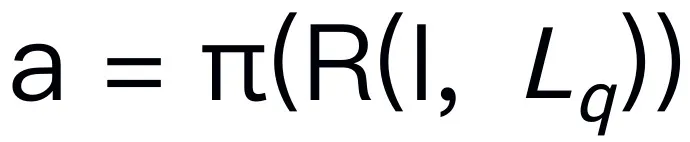 。根据之前的工作,我们使用 6-DoF 来表达 Franka Emika Panda 机械臂的末端执行器位姿。6 自由度包括末端执行器位置
。根据之前的工作,我们使用 6-DoF 来表达 Franka Emika Panda 机械臂的末端执行器位姿。6 自由度包括末端执行器位置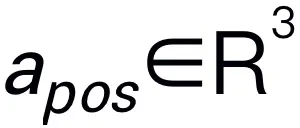 表示三维坐标,方向
表示三维坐标,方向 表示旋转矩阵。如果训练抓取任务,我们将抓夹状态添加到位姿预测中,从而实现 7-DoF 控制。
表示旋转矩阵。如果训练抓取任务,我们将抓夹状态添加到位姿预测中,从而实现 7-DoF 控制。
状态空间模型 (SSM)
本文选择 Mamba 作为大语言模型。Mamba 由许多 Mamba block 组成,最关键的组成部分是 SSM。SSM 是基于连续系统设计的,通过隐藏状态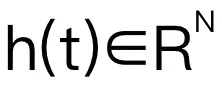 ,将 1D 输入序列
,将 1D 输入序列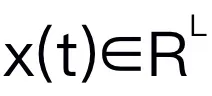 投影到 1D 输出序列
投影到 1D 输出序列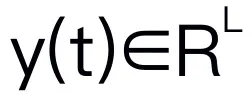 。SSM 由三个关键参数组成:状态矩阵
。SSM 由三个关键参数组成:状态矩阵 ,输入矩阵
,输入矩阵 ,输出矩阵
,输出矩阵 。SSM 可以表示为:
。SSM 可以表示为:
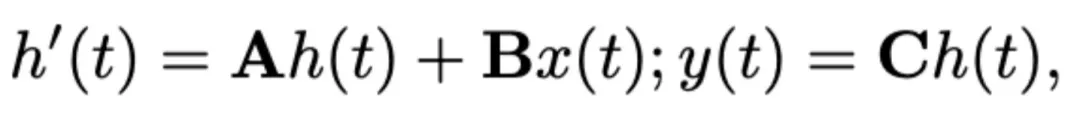
最近的 SSM (例如,Mamba) 被构造为使用时间尺度参数∆的离散连续系统。该参数将连续参数 A 和 B 转换为离散参数 和
和 。离散化采用零阶保持方法,定义如下:
。离散化采用零阶保持方法,定义如下:
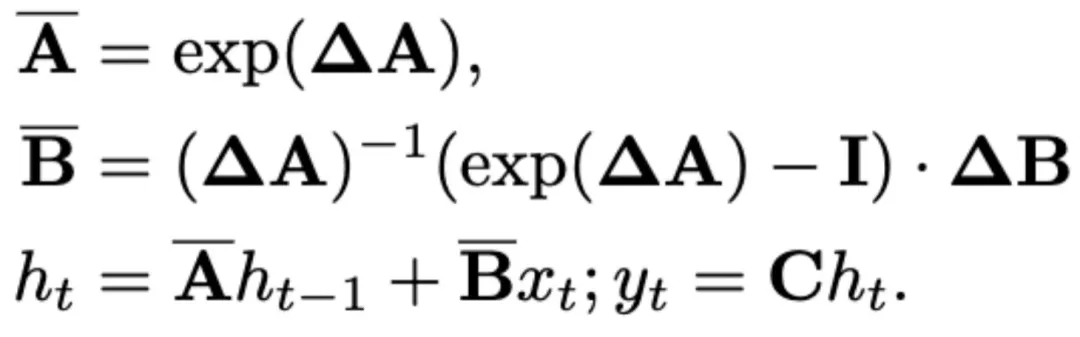
Mamba 引入了选择性扫描机制 (S6),在每个 Mamba block 中形成其 SSM 操作。SSM 参数更新为 ,实现更好的内容感知推理。下图 3 中展示了 Mamba block 的详细信息。
,实现更好的内容感知推理。下图 3 中展示了 Mamba block 的详细信息。
2. RoboMamba 模型结构
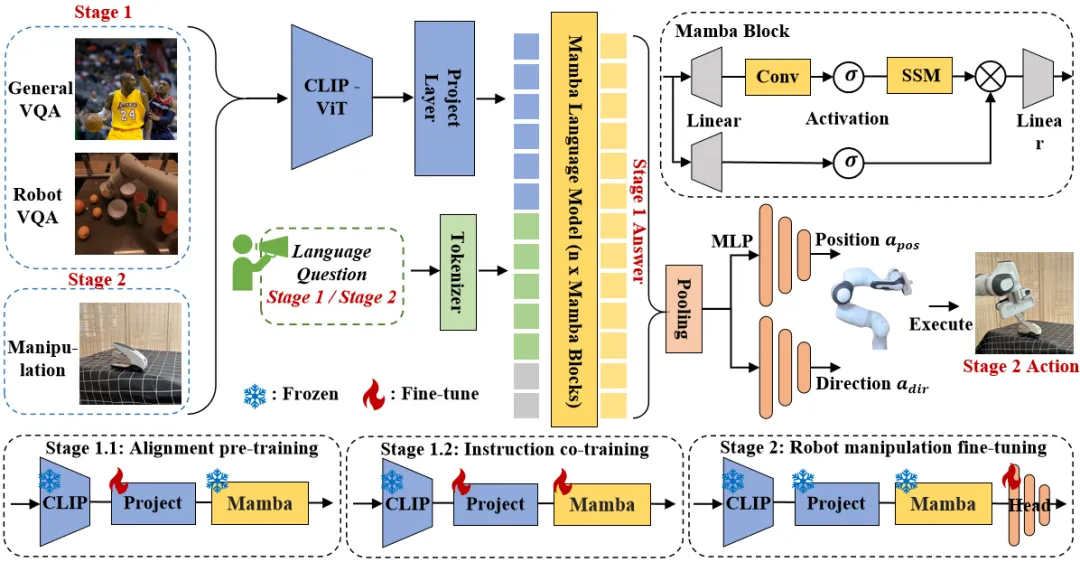
图 3. Robomamba 整体框架。RoboMamba 通过视觉编码器和投影层将图像投影到 Mamba 的语言嵌入空间,然后与文本 tokens 连接,并输入到 Mamba 模型中。为了预测末端执行器的位置和方向,我们引入简单的 MLP 策略头,并使用池化操作从语言输出 tokens 生成的全局 token 作为输入。RoboMamba 的训练策略。为了进行模型训练,我们将训练流程分为两个阶段。在 Stage 1,我们引入对齐预训练(Stage 1.1)和指令共同训练(Stage 1.2),以使 RoboMamba 具备常识推理和机器人相关的推理能力。在 Stage 2,我们提出机器人操作微调,以高效地赋予 RoboMamba Low-Level 操作技能。
为了使 RoboMamba 具备视觉推理和操作能力,我们从预训练的大语言模型(LLMs)和视觉模型开始,构建了一个高效的 MLLM 架构。如上图 3 所示,我们利用 CLIP 视觉编码器从输入图像 I 中提取视觉特征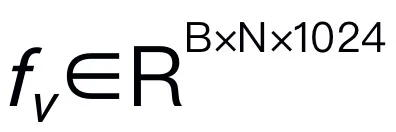 ,其中 B 和 N 分别表示 batch size 和 token 数。与最近的 MLLMs 不同,我们不采用视觉编码器集成技术,这种技术使用了多种骨干网络(即 DINOv2、CLIP-ConvNeXt、CLIP-ViT)进行图像特征提取。集成引入了额外的计算成本,严重影响了机器人 MLLM 在现实世界中的实用性。因此,我们证明了,当高质量数据和适当的训练策略结合时,简单且直接的模型设计也能实现强大的推理能力。为了使 LLM 理解视觉特征,我们使用多层感知器(MLP)将视觉编码器连接到 LLM。通过这个简单的跨模态连接器,RoboMamba 可以将视觉信息转换为语言嵌入空间
,其中 B 和 N 分别表示 batch size 和 token 数。与最近的 MLLMs 不同,我们不采用视觉编码器集成技术,这种技术使用了多种骨干网络(即 DINOv2、CLIP-ConvNeXt、CLIP-ViT)进行图像特征提取。集成引入了额外的计算成本,严重影响了机器人 MLLM 在现实世界中的实用性。因此,我们证明了,当高质量数据和适当的训练策略结合时,简单且直接的模型设计也能实现强大的推理能力。为了使 LLM 理解视觉特征,我们使用多层感知器(MLP)将视觉编码器连接到 LLM。通过这个简单的跨模态连接器,RoboMamba 可以将视觉信息转换为语言嵌入空间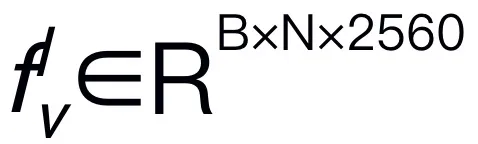 。
。
请注意,模型效率在机器人领域至关重要,因为机器人需要根据人类指令快速响应。因此,我们选择 Mamba 作为我们的大语言模型,因为它具有上下文感知推理能力和线性计算复杂度。文本提示使用预训练的分词器编码为嵌入空间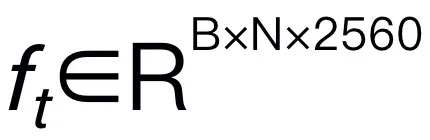 ,然后与视觉 token 连接(cat)并输入 Mamba。我们利用 Mamba 强大的序列建模来理解多模态信息,并使用有效的训练策略来开发视觉推理能力(如下一节所述)。输出 token (
,然后与视觉 token 连接(cat)并输入 Mamba。我们利用 Mamba 强大的序列建模来理解多模态信息,并使用有效的训练策略来开发视觉推理能力(如下一节所述)。输出 token (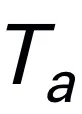 ) 然后被解码(det),生成自然语言响应
) 然后被解码(det),生成自然语言响应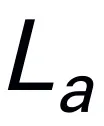 。模型的前向过程可以表示如下:
。模型的前向过程可以表示如下:
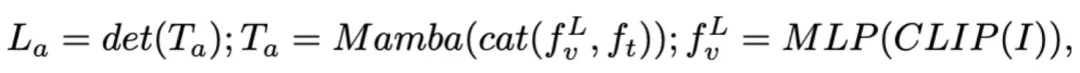
3.RoboMamba 通用视觉和机器人推理能力训练
在构建了 RoboMamba 架构后,接下来的目标是训练我们的模型学习通用视觉推理和机器人相关的推理能力。如图 3 所示,我们将 Stage 1 的训练分为两个子步骤:对齐预训练(Stage 1.1)和指令共同训练(Stage 1.2)。具体而言,与以往的 MLLM 训练方法不同,我们的目标是使 RoboMamba 能够理解通用视觉和机器人场景。鉴于机器人领域涉及许多复杂且新颖的任务,RoboMamba 需要更强的泛化能力。因此,我们在 Stage 1.2 阶段采用了共同训练策略,将高层次的机器人数据(例如任务规划)与通用指令数据结合起来。我们发现,共同训练不仅可以获得更具泛化能力的机器人策略,还由于机器人数据中的复杂推理任务而带来的通用场景推理能力增强。训练细节如下:
Stage 1.1:对齐预训练。
我们采用 LLaVA 过滤的 558k 图像 - 文本配对数据集进行跨模态对齐。如图 3 所示,我们冻结 CLIP 编码器和 Mamba 语言模型的参数,仅更新投影层。通过这种方式,我们可以将图像特征与预训练的 Mamba 词嵌入对齐。
Stage 1.2:指令共同训练。
在这一阶段,我们首先遵循先前 MLLM 的工作进行通用视觉指令数据收集。我们采用了 655K LLaVA 混合指令数据集和 400K LRV-Instruct 数据集,分别用于学习视觉指令跟随和减轻幻觉。需要注意的是,减轻幻觉在机器人场景中起着重要作用,因为机器人 MLLM 需要基于真实场景生成任务规划,而不是想象中的场景。例如,现有的 MLLMs 可能公式化地回答 “打开微波炉” 时说 “步骤 1:找到把手”,但许多微波炉没有把手。接下来,我们结合了 800K RoboVQA 数据集,以学习高层次的机器人技能,如长程任务规划、可操纵性判断、可操纵性生成、未来与过去预测等。在共同训练期间,如图 3 所示,我们冻结 CLIP 编码器的参数,并在 1.8m 合并数据集上微调投影层和 Mamba。所有来自 Mamba 语言模型的输出都使用交叉熵损失进行监督。
4.RoboMamba 操纵能力微调训练
在 RoboMamba 强大的推理能力基础上,我们在本节介绍了我们的机器人操作微调策略,在图 3 中称为训练 Stage 2。现有的基于 MLLM 的机器人操作方法在操作微调阶段需要更新投影层和整个 LLM。虽然这种范式可以赋予模型动作位姿预测能力,但它也破坏了 MLLM 的固有能力,并且需要大量的训练资源。为了解决这些挑战,我们提出了一种高效的微调策略,如图 3 所示。我们冻结 RoboMamba 的所有参数,并引入一个简单的 Policy head 来建模 Mamba 的输出 token。Policy head 包含两个 MLP 分别学习末端执行器位置和方向,总共占用整个模型参数的 0.1%。根据前期工作 where2act,位置和方向的损失公式如下:
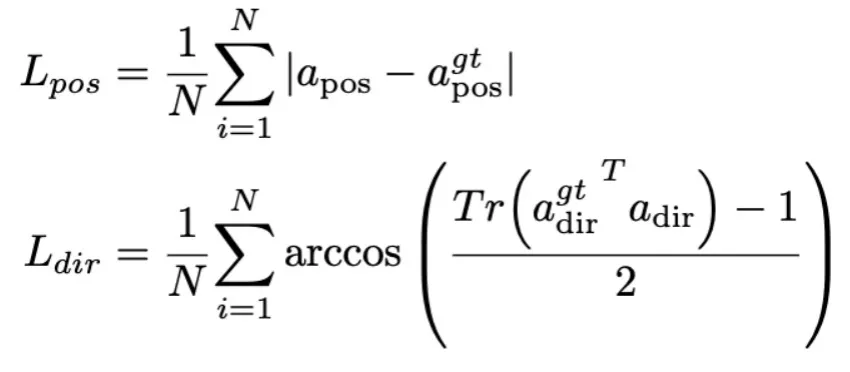
其中,N 表示训练样本的数量,Tr (A) 表示矩阵 A 的迹。RoboMamba 只预测图像中接触像素的二维位置(x, y),然后使用深度信息将其转换为三维空间。为了评估这一微调策略,我们使用 SAPIEN 模拟生成了一个包含 1 万条末端执行器位姿预测的数据集。
在操作微调之后,我们发现一旦 RoboMamba 具备了足够的推理能力,它可以通过极高效的微调来获取位姿预测技能。由于微调参数(7MB)极少且模型设计高效,我们只需 20 分钟即可实现新的操作技能学习。这一发现突出了推理能力对于学习操作技能的重要性,并提出了一个新的视角:我们可以在不影响 MLLM 固有推理能力的情况下,高效地赋予其操作能力。最后,RoboMamba 可以使用语言响应进行常识和与机器人相关的推理,并使用 Policy head 进行动作位姿预测。
定量实验
1. 通用推理能力评估(MLLM Benchmarks)
为了评估推理能力,我们使用了几个流行的基准,包括 VQAv2、OKVQA、GQA、OCRVQA、VizWiz、POPE、MME、MMBench 和 MM-Vet。除此之外,我们还在 RoboVQA 的 18k 验证数据集上直接评估了 RoboMamba 的机器人相关推理能力,涵盖了机器人任务,如任务规划、提示性任务规划、长程任务规划、可操纵性判断、可操纵性生成、过去描述和未来预测等。
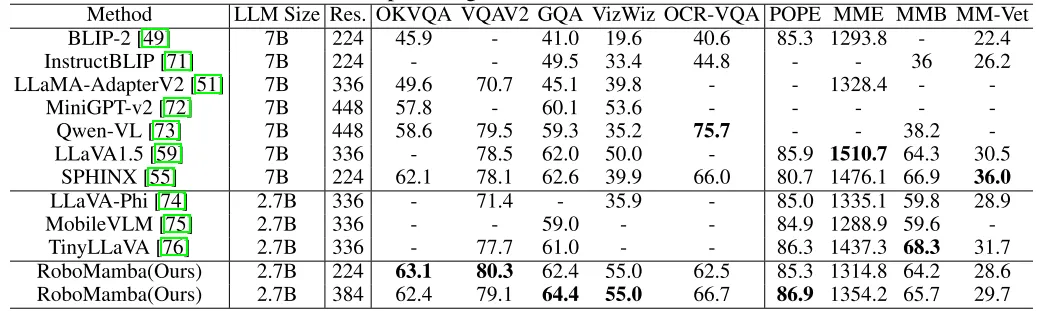
表 1. Robomamba 与现有 MLLMs 在多个基准上的通用推理能力比较。
如表 1 所示,我们将 RoboMamba 与以前最先进的 (SOTA) MLLM 在通用的 VQA 和最近的 MLLM 基准测试上进行比较。首先,我们发现 RoboMamba 仅使用 2.7B 语言模型,就在所有 VQA 基准测试中取得了令人满意的结果。结果表明,简单的结构设计是有效的。对齐预训练和指令协同训练显著提高了 MLLM 的推理能力。例如,由于在协同训练阶段引入了大量的机器人数据,RoboMamba 在 GQA 基准上的空间识别性能得到了提高。同时,我们还在最近提出的 MLLM 基准上测试了我们的 RoboMamba。与以前的 MLLMs 相比,我们观察到我们的模型在所有基准测试中都取得了具有竞争力的结果。虽然 RoboMamba 的一些性能仍然低于最先进的 7B MLLM (e.g., LLaVA1.5 和 SPHINX),但我们优先使用更小更快的 Mamba-2.7B 来平衡机器人模型的效率。在未来,我们计划为资源不受限制的场景开发 RoboMamba-7B。
2. 机器人推理能力评估(RoboVQA Benchmark)
另外,为了全面比较 RoboMamba 与机器人相关的推理能力,我们在 RoboVQA 验证集上与 LLaMA-AdapterV2 进行基准测试。我们选择 LLaMA-AdapterV2 作为基准,因为它是当前 SOTA 机器人 MLLM (ManipLLM) 的基础模型。为了进行公平的比较,我们加载了 LLaMA-AdapterV2 预训练参数,并使用其官方指令微调方法在 RoboVQA 训练集上对其进行了两个 epoch 的微调。如图 4 a)所示,RoboMamba 在 BLEU-1 到 BLEU-4 之间实现了卓越的性能。结果表明,我们的模型具有先进的机器人相关推理能力,并证实了我们的训练策略的有效性。除了更高的准确率外,我们的模型实现的推理速度比 LLaMA-AdapterV2 和 ManipLLM 快 7 倍,这可以归因于 Mamba 语言模型的内容感知推理能力和效率。
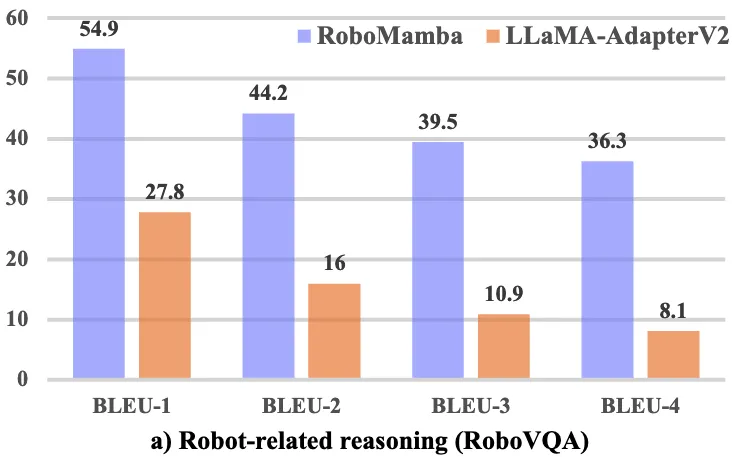
图 4. RoboVQA 上与机器人相关的推理对比。
3. 机器人操纵能力评估(SAPIEN)
为了评估 RoboMamba 的操作能力,我们将我们的模型与四个基线进行了比较:UMPNet, Flowbot3D, RoboFlamingo 和 ManipLLM。在比较之前,我们复现所有基线并在我们收集的数据集上训练它们。对于 UMPNet,我们在预测的接触点上执行操作,方向垂直于物体表面。Flowbot3D 在点云上预测运动方向,选择最大的流作为交互点,并使用流方向表示末端执行器的方向。RoboFlamingo 和 ManipLLM 分别加载 OpenFlamingo 和 LLaMA-AdapterV2 预训练参数,并遵循各自的微调和模型更新策略。如表 2 所示,与之前的 SOTA ManipLLM 相比,我们的 RoboMamba 在可见类别上实现了 7.0% 的改进,在不可见类别上实现了 2.0% 的改进。在效率方面,RoboFlamingo 更新了 35.5% (1.8B) 的模型参数,ManipLLM 更新了 LLM 中的适配器 (41.3M),包含 0.5% 的模型参数,而我们的微调 Policy head (3.7M) 仅占模型参数的 0.1%。RoboMamba 比以前基于 MLLM 的方法更新的参数少了 10 倍,而推理速度提高了 7 倍。结果表明,我们的 RoboMamba 不仅具有强大的推理能力,而且能够以低成本的方式获得操纵能力。
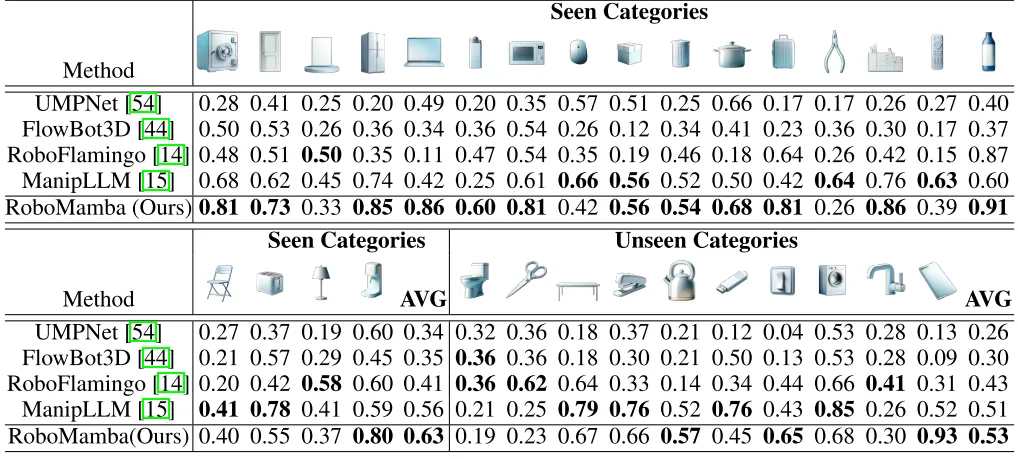
表 2. Robomamba 与其他 baseline 的成功率比较
定性结果

图 4. RoboMamba 面对现实世界中各种机器人下游任务的可视化。
如图 4 所示,我们可视化了 RoboMamba 在各种机器人下游任务中的推理结果。在任务规划方面,相较于 LLaMA-AdapterV2, RoboMamba 凭借其强大的推理能力,展现出了更准确、更长远的规划能力。为了进行公平的比较,我们还对 RoboVQA 数据集上的基准 LLaMA-AdapterV2 进行了微调。对于操纵位姿预测,我们使用了 Franka Emika 机械臂来与各种家庭物品进行交互。我们将 RoboMamba 预测的 3D 位姿投影到 2D 图像上,使用红点表示接触点,末端执行器表示方向,如图右下角所示。







还没有评论,来说两句吧...