

为了将大型语言模型(LLM)与人类的价值和意图对齐,学习人类反馈至关重要,这能确保它们是有用的、诚实的和无害的。在对齐 LLM 方面,一种有效的方法是根据人类反馈的强化学习(RLHF)。尽管经典 RLHF 方法的结果很出色,但其多阶段的过程依然带来了一些优化难题,其中涉及到训练一个奖励模型,然后优化一个策略模型来最大化该奖励。
近段时间已有一些研究者探索了更简单的离线算法,其中之一便是直接偏好优化(DPO)。DPO 是通过参数化 RLHF 中的奖励函数来直接根据偏好数据学习策略模型,这样就无需显式的奖励模型了。该方法简单稳定,已经被广泛用于实践。
使用 DPO 时,得到隐式奖励的方式是使用当前策略模型和监督式微调(SFT)模型之间的响应似然比的对数 的对数比。但是,这种构建奖励的方式并未与引导生成的指标直接对齐,该指标大约是策略模型所生成响应的平均对数似然。训练和推理之间的这种差异可能导致性能不佳。
为此,弗吉尼亚大学的助理教授孟瑜与普林斯顿大学的在读博士夏梦舟和助理教授陈丹琦三人共同提出了 SimPO—— 一种简单却有效的离线偏好优化算法。

论文标题:SimPO: Simple Preference Optimization with a Reference-Free Reward
论文地址:https://arxiv.org/pdf/2405.14734
代码 & 模型:https://github.com/princeton-nlp/SimPO
该算法的核心是将偏好优化目标中的奖励函数与生成指标对齐。SimPO 包含两个主要组件:(1)在长度上归一化的奖励,其计算方式是使用策略模型的奖励中所有 token 的平均对数概率;(2)目标奖励差额,用以确保获胜和失败响应之间的奖励差超过这个差额。
总结起来,SimPO 具有以下特点:
简单:SimPO 不需要参考模型,因此比 DPO 等其它依赖参考模型的方法更轻量更容易实现。
性能优势明显:尽管 SimPO 很简单,但其性能却明显优于 DPO 及其最新变体(比如近期的无参考式目标 ORPO)。如图 1 所示。并且在不同的训练设置和多种指令遵从基准(包括 AlpacaEval 2 和高难度的 Arena-Hard 基准)上,SimPO 都有稳定的优势。
尽量小的长度利用:相比于 SFT 或 DPO 模型,SimPO 不会显著增加响应长度(见表 1),这说明其长度利用是最小的。
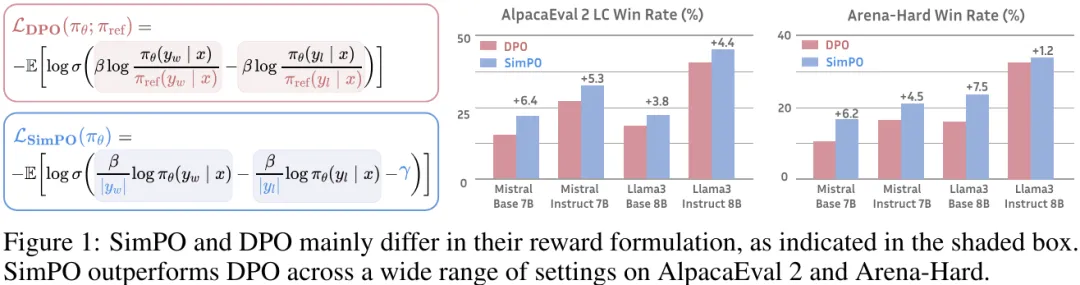
该团队进行了大量分析,结果表明 SimPO 能更有效地利用偏好数据,从而在验证集上对高质量和低质量响应的似然进行更准确的排序,这进一步能造就更好的策略模型。
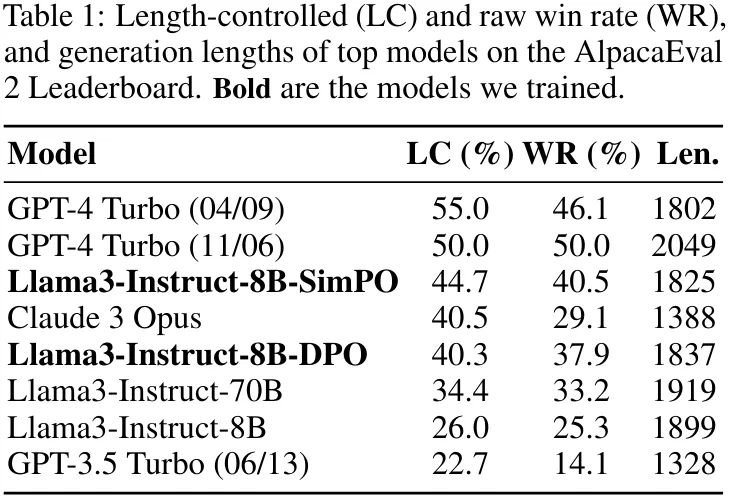
如表 1 所示,该团队基于 Llama3-8B-instruct 构建了一个具有顶尖性能的模型,其在 AlpacaEval 2 上得到的长度受控式胜率为 44.7,在排行榜上超过了 Claude 3 Opus;另外其在 Arena-Hard 上的胜率为 33.8,使其成为了目前最强大的 8B 开源模型。
SimPO:简单偏好优化
为便于理解,下面首先介绍 DPO 的背景,然后说明 DPO 的奖励与生成所用的似然度量之间的差异,并提出一种无参考的替代奖励公式来缓解这一问题。最后,通过将目标奖励差额项整合进 Bradley-Terry 模型中,推导出 SimPO 目标。
背景:直接偏好优化(DPO)
DPO 是最常用的离线偏好优化方法之一。DPO 并不会学习一个显式的奖励模型,而是使用一个带最优策略的闭式表达式来对奖励函数 r 进行重新参数化:
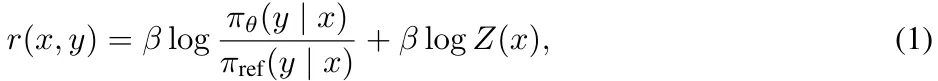
其中 π_θ 是策略模型,π_ref 是参考策略(通常是 SFT 模型),Z (x) 是配分函数。通过将这种奖励构建方式整合进 Bradley-Terry (BT) 排名目标,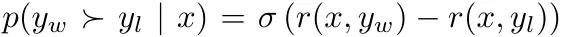 ,DPO 可使用策略模型而非奖励模型来表示偏好数据的概率,从而得到以下目标:
,DPO 可使用策略模型而非奖励模型来表示偏好数据的概率,从而得到以下目标:
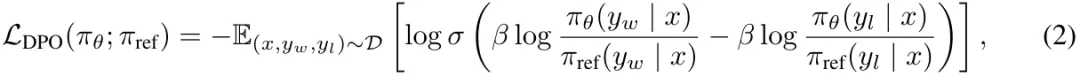
其中 (x, y_w, y_l) 是由来自偏好数据集 D 的 prompt、获胜响应和失败响应构成的偏好对。
一种与生成结果对齐的简单无参考奖励
DPO 的奖励与生成之间的差异。使用 (1) 式作为隐式的奖励表达式有以下缺点:(1) 训练阶段需要参考模型 π_ref,这会带来额外的内存和计算成本;(2) 训练阶段优化的奖励与推理所用的生成指标之间存在差异。具体来说,在生成阶段,会使用策略模型 π_θ 生成一个能近似最大化平均对数似然的序列,定义如下:
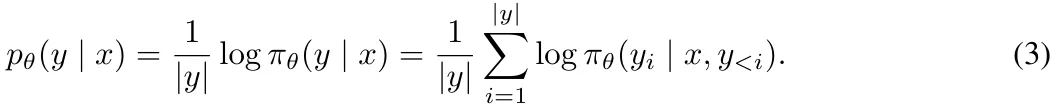
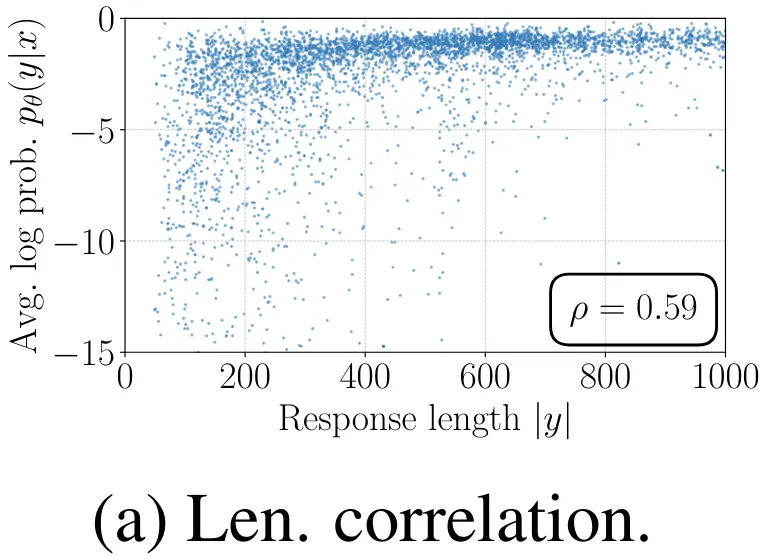
在解码过程中直接最大化该指标是非常困难的,为此可以使用多种解码策略,如贪婪解码、波束搜索、核采样和 top-k 采样。此外,该指标通常用于在语言模型执行多选任务时对选项进行排名。在 DPO 中,对于任意三元组 (x, y_w, y_l),满足奖励排名 r (x, y_w) > r (x, y_l) 并不一定意味着满足似然排名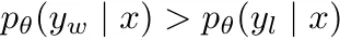 。事实上,在使用 DPO 训练时,留存集中大约只有 50% 的三元组满足这个条件(见图 4b)。
。事实上,在使用 DPO 训练时,留存集中大约只有 50% 的三元组满足这个条件(见图 4b)。
构建在长度上归一化的奖励。很自然地,我们会考虑使用 (3) 式中的 p_θ 来替换 DPO 中的奖励构建,使其与引导生成的似然指标对齐。这会得到一个在长度上归一化的奖励:
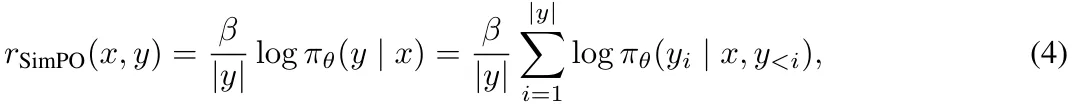
其中 β 是控制奖励差异大小的常量。该团队发现,根据响应长度对奖励进行归一化非常关键;从奖励公式中移除长度归一化项会导致模型倾向于生成更长但质量更低的序列。这样一来,构建的奖励中就无需参考模型了,从而实现比依赖参考模型的算法更高的内存和计算效率。
SimPO 目标
目标奖励差额。另外,该团队还为 Bradley-Terry 目标引入了一个目标奖励差额项 γ > 0,以确保获胜响应的奖励 r (x, y_w) 超过失败响应的奖励 r (x, y_l) 至少 γ:
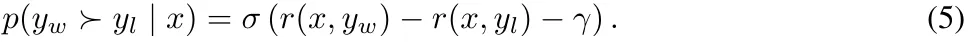
两个类之间的差额已知会影响分类器的泛化能力。在使用随机模型初始化的标准训练设置中,增加目标差额通常能提升泛化性能。在偏好优化中,这两个类别是单个输入的获胜或失败响应。
在实践中,该团队观察到随着目标差额增大,生成质量一开始会提升,但当这个差额变得过大时,生成质量就会下降。DPO 的一种变体 IPO 也构建了与 SimPO 类似的目标奖励差额,但其整体目标的效果不及 SimPO。
目标。最后,通过将 (4) 式代入到 (5) 式中,可以得到 SimPO 目标:
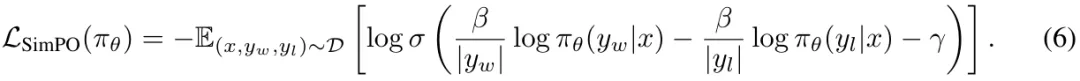
总结起来,SimPO 采用了与生成指标直接对齐的隐式奖励形式,从而消除了对参考模型的需求。此外,其还引入了一个目标奖励差额 γ 来分离获胜和失败响应。
实验设置
模型和训练设置。该团队的实验使用了 Base 和 Instruct 两种设置下的两类模型 Llama3-8B 和 Mistral-7B。
评估基准。该团队使用了三个最常用的开放式指令遵从基准:MT-Bench、AlpacaEval 2 和 Arena-Hard v0.1。这些基准可评估模型在各种查询上的多样化对话能力,并已被社区广泛采用。表 2 给出了一些细节。

基线方法。表 3 列出了与 SimPO 做对比的其它离线偏好优化方法。

实验结果
主要结果与消融研究
SimPO 的表现总是显著优于之前已有的偏好优化方法。如表 4 所示,尽管所有的偏好优化算法的表现都优于 SFT 模型,但简单的 SimPO 却在所有基准和设置上都取得了最佳表现。这样全面的大幅领先彰显了 SimPO 的稳健性和有效性。
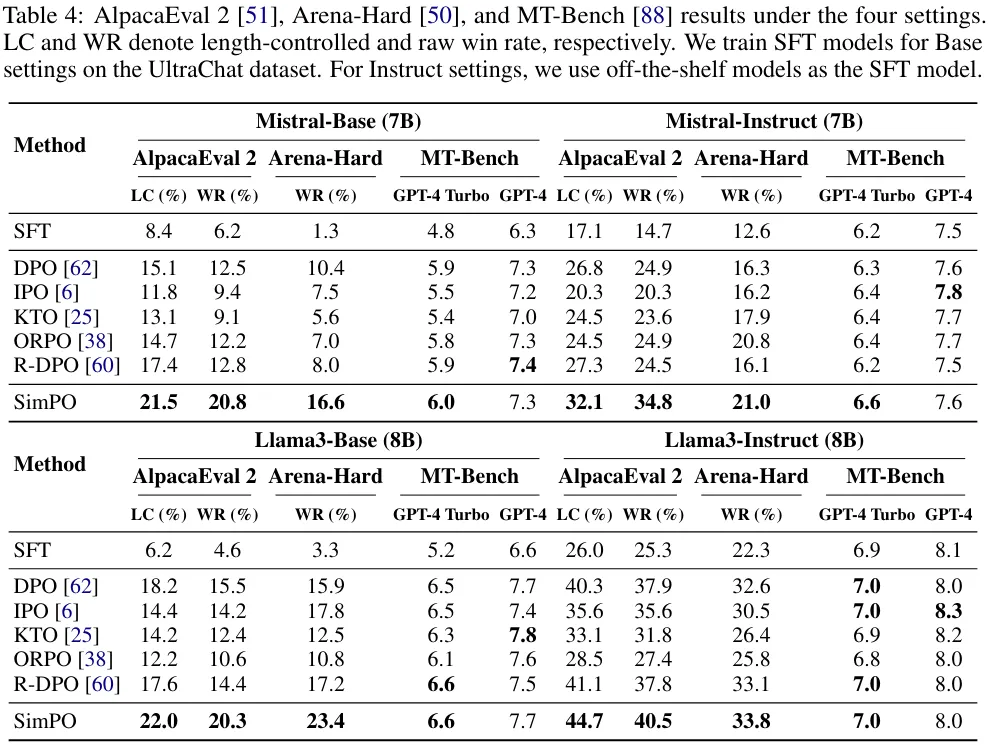
基准质量各不相同。可以观察到,在 Arena-Hard 上的胜率明显低于在 AlpacaEval 2 上胜率,这说明 Arena-Hard 是更困难的基准。
Instruct 设置会带来显著的性能增益。可以看到,Instruct 设置在所有基准上都全面优于 Base 设置。这可能是因为这些模型使用了更高质量的 SFT 模型来进行初始化以及这些模型生成的偏好数据的质量更高。
SimPO 的两种关键设计都很重要。表 5 展示了对 SimPO 的每种关键设计进行消融实验的结果。(1) 移除 (4) 式中的长度归一化(即 w/o LN);(2) 将 (6) 式中的目标奖励差额设置为 0(即 γ = 0)。
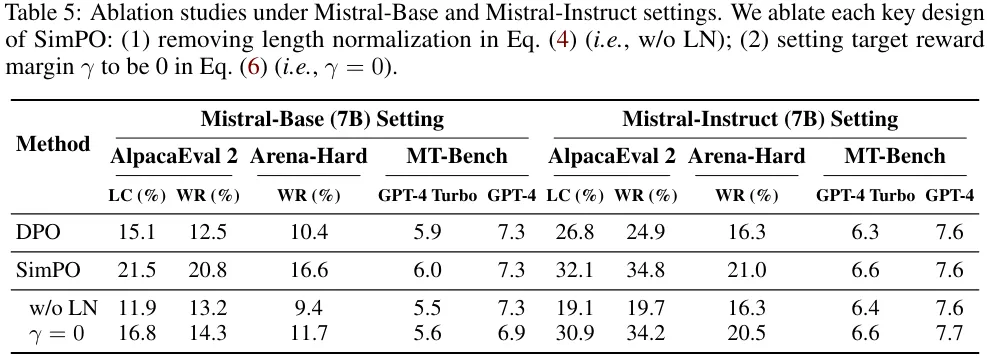
移除长度归一化对结果的影响最大。该团队研究发现,这会导致模型生成长且重复的模式,由此严重拉低输出的整体质量。将 γ 设为 0 也会导致 SimPO 的性能下降,这说明 0 并非最优的目标奖励差额。
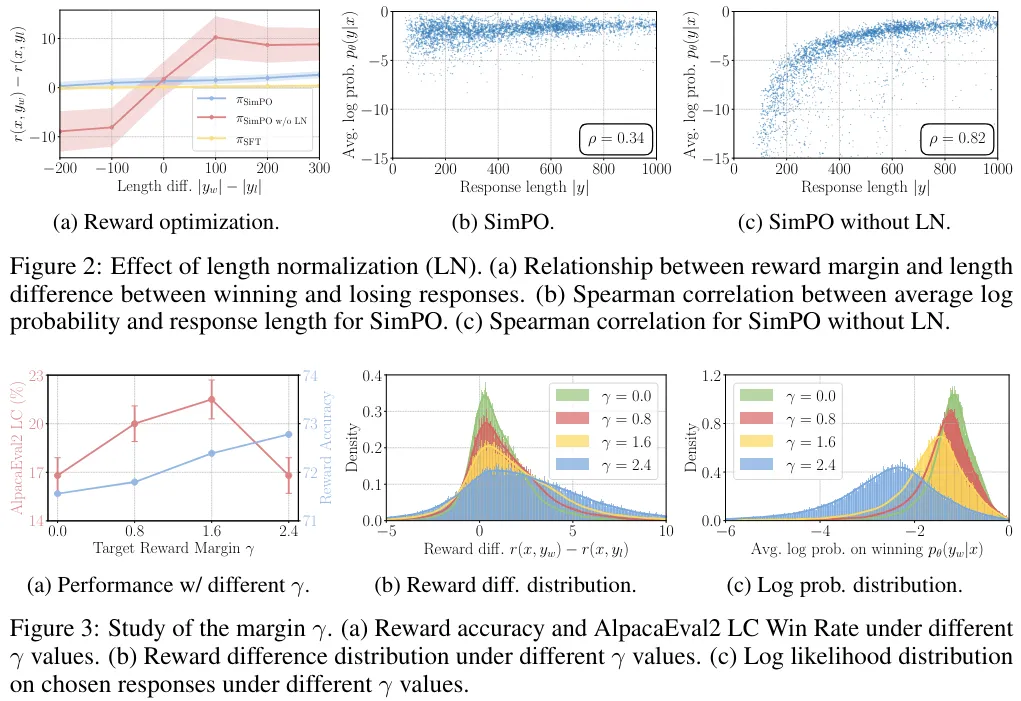
有关这两项设计选择的更深度分析请参阅原论文。
深度对比 DPO 与 SimPO
最后,该团队还从四个角度全面比较了 DPO 与 SimPO:(1) 似然 - 长度相关性、(2) 奖励构建、(3) 奖励准确度、(4) 算法效率。结果表明 SimPO 在准确度和效率方面优于 DPO。
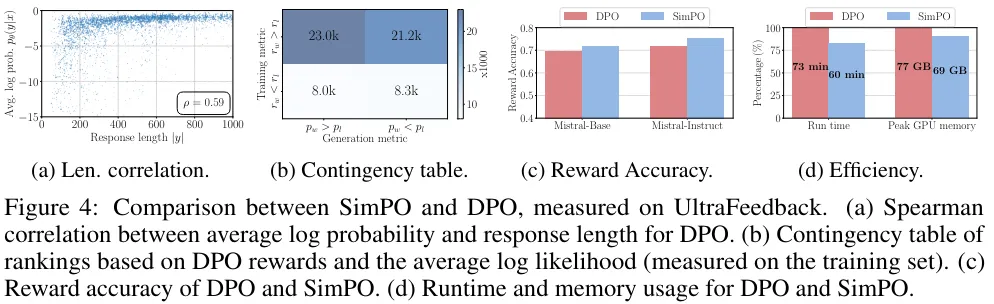
DPO 奖励会隐式地促进长度归一化。
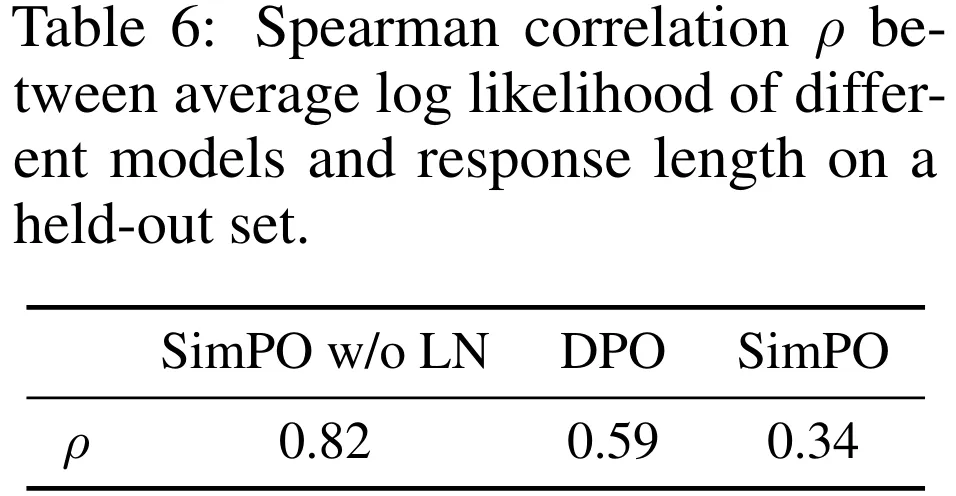
尽管 DPO 奖励表达式 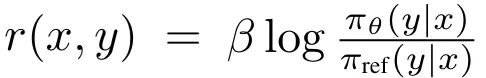 (不包含配分函数)缺乏一个用于长度归一化的显式项,但策略模型和参考模型之间的对数比可以隐式地抵消长度偏见。如表 6 与图 4a 所示,相比于没有任何长度归一化的方法(记为 SimPO w/o LN),使用 DPO 会降低平均对数似然和响应长度之间的斯皮尔曼相关系数。但是,当与 SimPO 比较时,其仍然表现出更强的正相关性。
(不包含配分函数)缺乏一个用于长度归一化的显式项,但策略模型和参考模型之间的对数比可以隐式地抵消长度偏见。如表 6 与图 4a 所示,相比于没有任何长度归一化的方法(记为 SimPO w/o LN),使用 DPO 会降低平均对数似然和响应长度之间的斯皮尔曼相关系数。但是,当与 SimPO 比较时,其仍然表现出更强的正相关性。
DPO 奖励与生成似然不匹配。
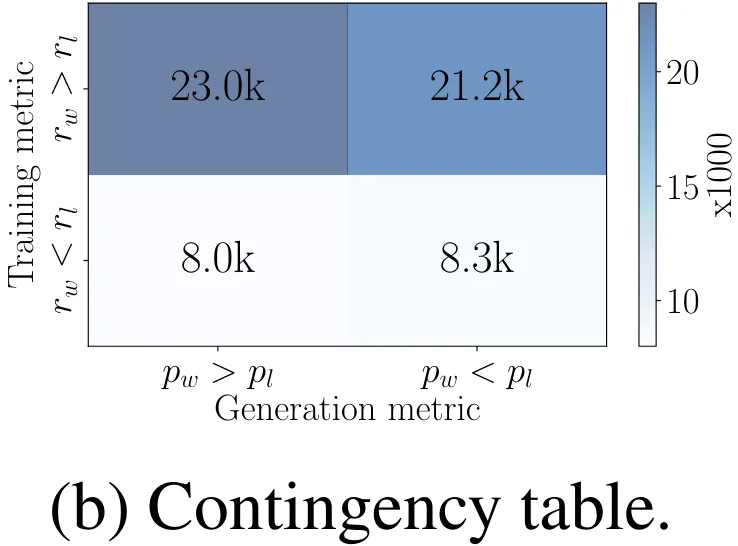
DPO 的奖励与平均对数似然指标之间存在差异,这会直接影响生成。如图 4b 所示,在 UltraFeedback 训练集上的实例中,其中 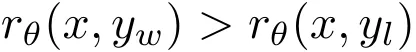 ,几乎一半的数据对都有
,几乎一半的数据对都有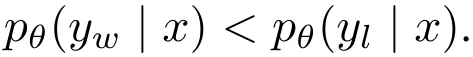 。相较之下,SimPO 是直接将平均对数似然(由 β 缩放)用作奖励表达式,由此完全消除了其中的差异。
。相较之下,SimPO 是直接将平均对数似然(由 β 缩放)用作奖励表达式,由此完全消除了其中的差异。
DPO 在奖励准确度方面不及 SimPO。
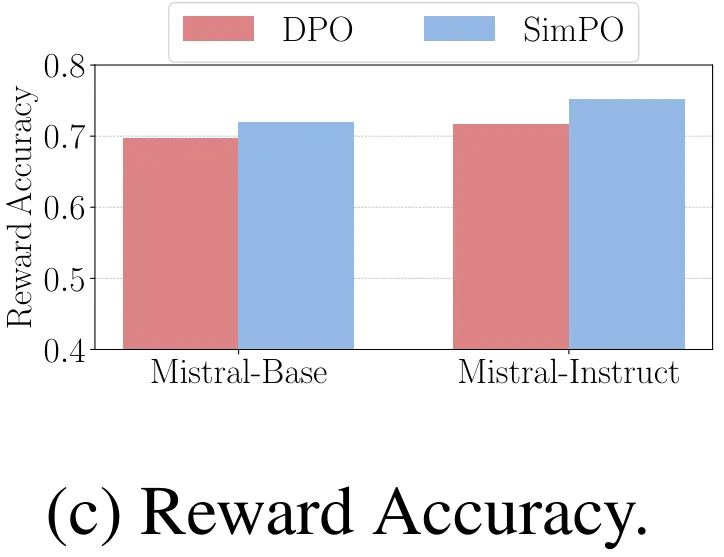
图 4c 比较了 SimPO 和 DPO 的奖励准确度,这评估的是它们最终学习到的奖励与留存集上的偏好标签的对齐程度。可以观察到,SimPO 的奖励准确度高于 DPO,这说明 SimPO 的奖励设计有助于实现更有效的泛化和更高质量的生成。
SimPO 的内存效率和计算效率都比 DPO 高。
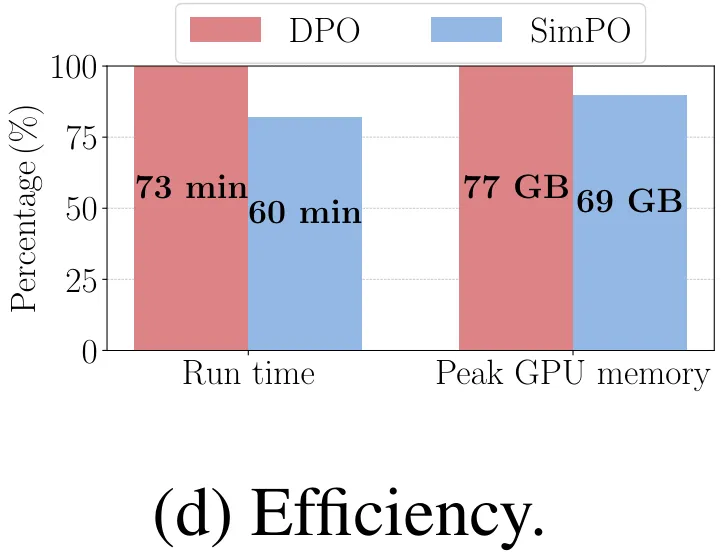
SimPO 的另一大优势是效率,毕竟它不使用参考模型。图 4d 给出了在 8×H100 GPU 上使用 Llama3-Base 设置时,SimPO 和 DPO 的整体运行时间和每台 GPU 的峰值内存使用量。相比于原版 DPO 实现,得益于消除了使用参考模型的前向通过,SimPO 可将运行时间降低约 20%,将 GPU 内存使用量降低约 10%。
更多详细内容,请阅读原文。




还没有评论,来说两句吧...