

多模态大模型家族,又有新成员了!
不仅能将多张图像与文本结合分析,还能处理视频中的时空关系。
这款免费开源的模型,在MMbench和MME榜单同时登顶,目前浮动排名也保持在前三位。
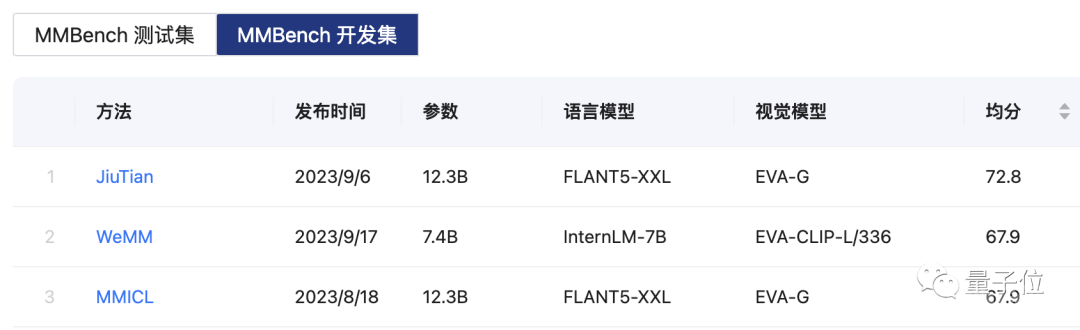
△MMBench榜单,MMBench是上海AI lab和南洋理工大学联合推出的基于ChatGPT的全方位多模能力评测体系
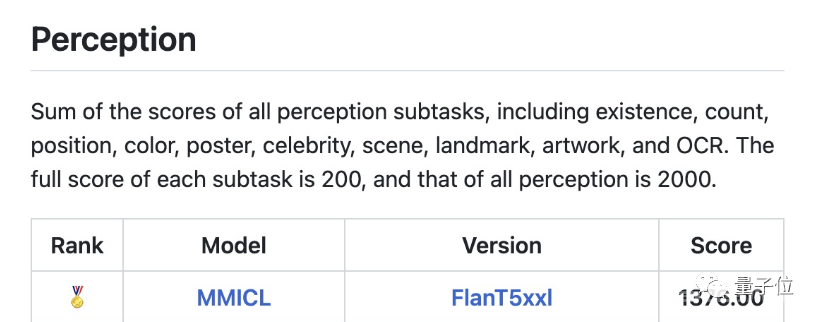
△MME榜单,MME为腾讯优图实验室联合厦门大学开展的多模态大语言模型测评
这款多模态大模型名叫MMICL,由北京交通大学、北京大学、UCLA、足智多模公司等机构联合推出。
MMICL一共有两个基于不同LLM的版本,分别基于Vicuna和FlanT5XL两种核心模型。
这两个版本都已经开源,其中,FlanT5XL版可以商用,Vicuna版本只能用于科研用途。
在MME的多项任务测试中,FlanT5XL版MMICL的成绩已连续数周保持着领先地位。
其中认知方面取得了428.93的总成绩(满分800),位列第一,大幅超过了其他模型。
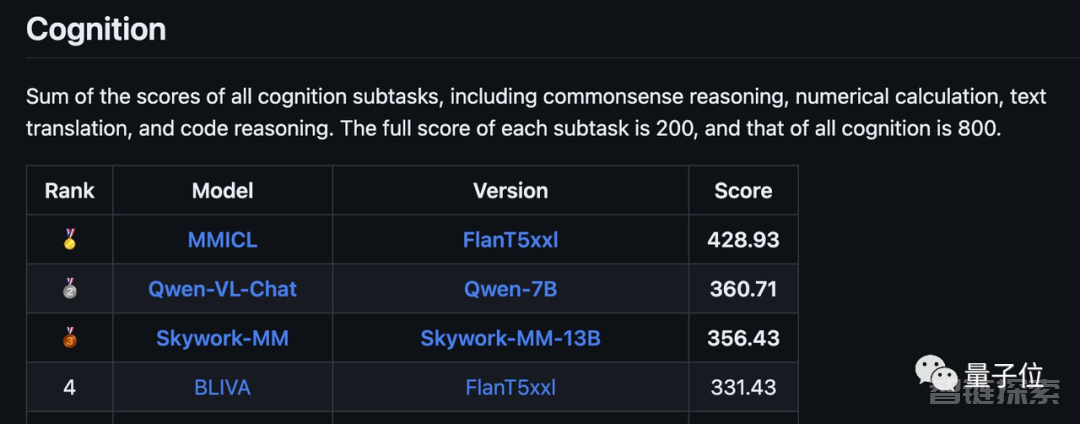
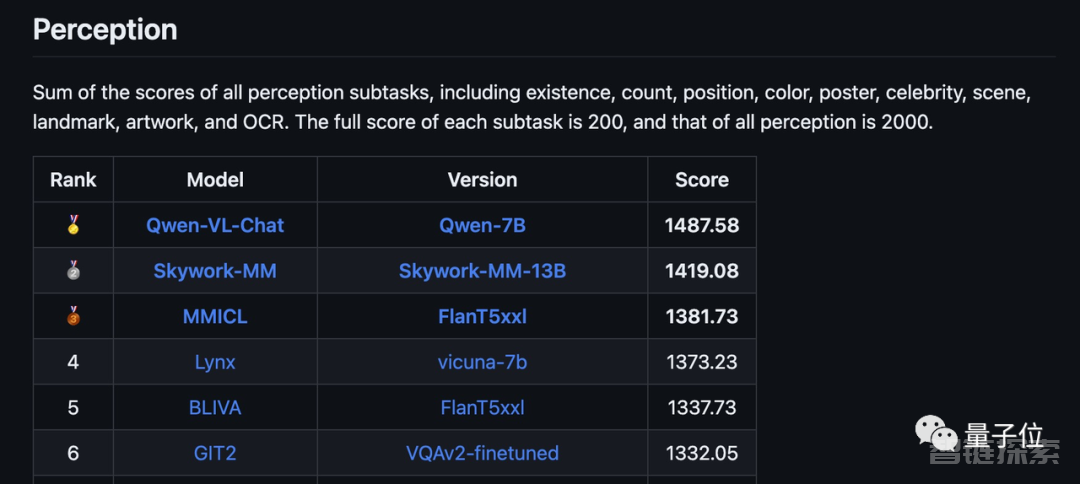
感知方面的总分1381.78(满分2000),在最新版榜单中仅次于阿里的千问-7B和昆仑万维的天工模型。
所需配置方面,官方给出的说法是在训练阶段需要6块A40,推理阶段则可以在一块A40上运行。
仅仅只需要从开源数据集中构建的0.5M的数据即可完成第二阶段的训练,耗时仅需几十小时。
那么,这个多模态大模型都有哪些特色呢?
会看视频,还能“现学现卖”
MMICL支持文本和图片穿插形式的prompt,用起来就像微信聊天一样自然。
用正常说话的方式把两张图喂给MMICL,就可以分析出它们的相似和不同之处。

除了超强的图像分析能力,MMICL还知道“现学现卖”。
比如我们丢给MMICL一张“我的世界”中像素风格的马。
由于训练数据都是真实世界的场景,这种过于抽象的像素风MMICL并不认识。

但我们只要让MMICL学习几个例子,它便能很快地进行类比推理。
下图中,MMICL分别学习了有马、驴和什么都没有这三种场景,然后便正确判断出了更换背景后的像素马。

除了图片,动态的视频也难不倒MMICL,不仅是理解每一帧的内容,还能准确地分析出时空关系。
不妨来看一下这场巴西和阿根廷的足球大战,MMICL准确地分析出了两支队伍的行动。

针对视频当中的细节,也可以向MMICL提问,比如巴西球员是怎么阻挡阿根廷队员的。

除了准确把握视频中的时空关系,MMICL还支持实时视频流输入。
我们可以看到,监控画面中的人正在摔倒,MMICL检测到了这一异常现象并发出了提示,询问是否需要帮助。

如果把MME榜上感知和认知两项的前五名放在一张图里比较,我们可以看出,MMICL的表现在各个方面都有不俗的成绩。
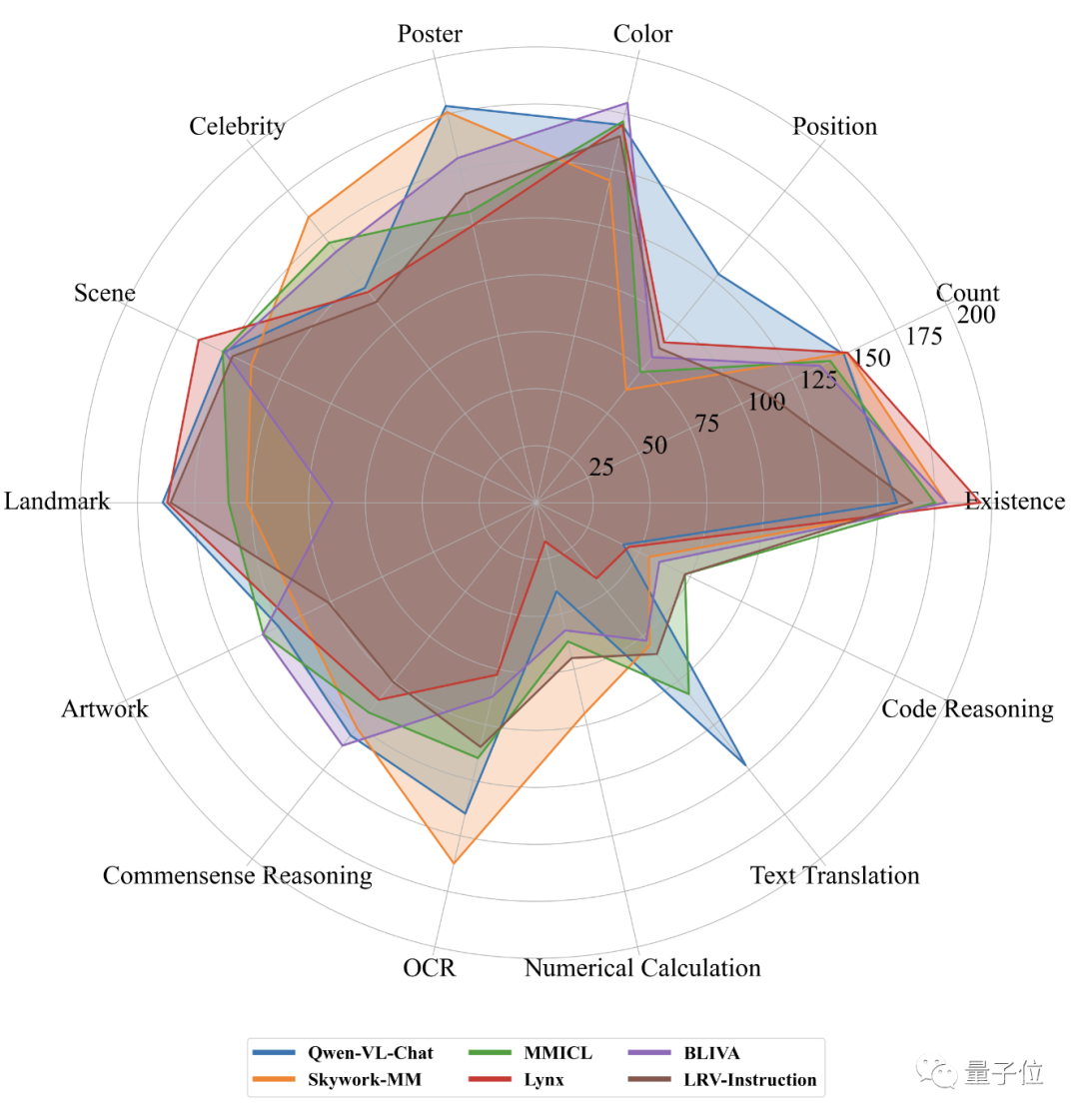
那么,MMICL是如何做到的,背后又有什么样的技术细节呢?
训练分两阶段完成
MMICL致力于解决视觉语言模型在理解具有多个图像的复杂多模态输入方面遇到的问题。
MMICL利用Flan-T5 XXL模型作为骨干,整个模型的结构和流程如下图所示:
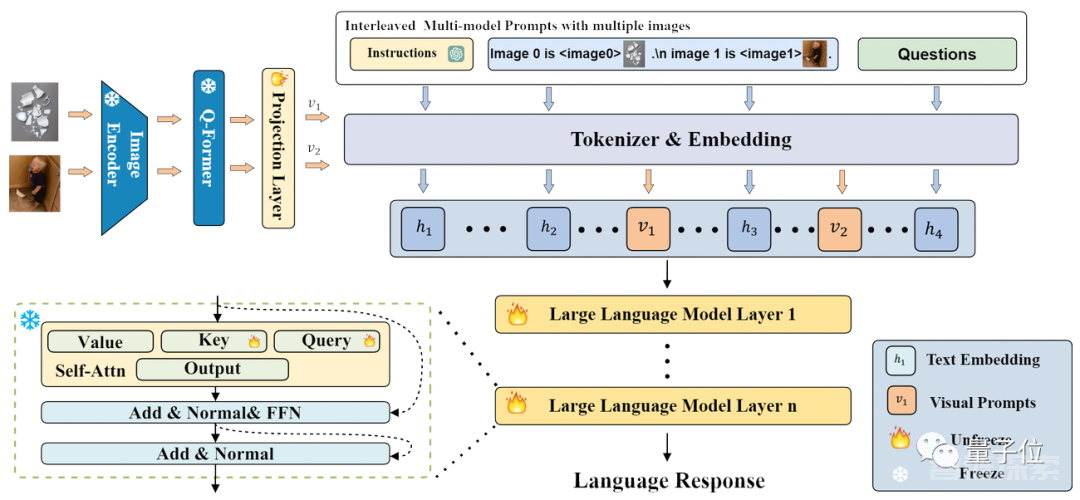
MMICL使用类似于BLIP2的结构,但是能够接受交错的图文的输入。
MMICL将图文平等对待,把处理后的图文特征,都按照输入的格式,拼接成图文交错的形式输入到语言模型中进行训练和推理。
类似于InstructBLIP,MMICL的开发过程是将LLM冻结,训练Q-former,并在特定数据集上对其进行微调。
MMICL的训练流程和数据构造如下图所示:
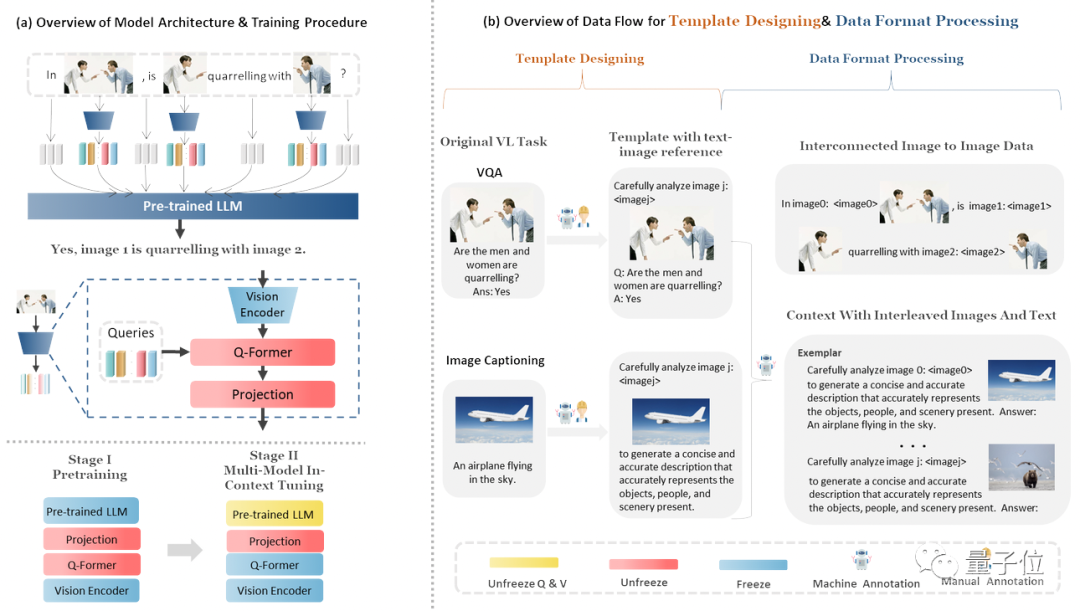
具体来说,MMICL的训练一共分成了两个阶段:
预训练阶段,使用了LAION-400M(参考LLaVA)数据集
多模态in-context tuning,使用了自有的MIC(Multi-Model In-Context Learning)数据集
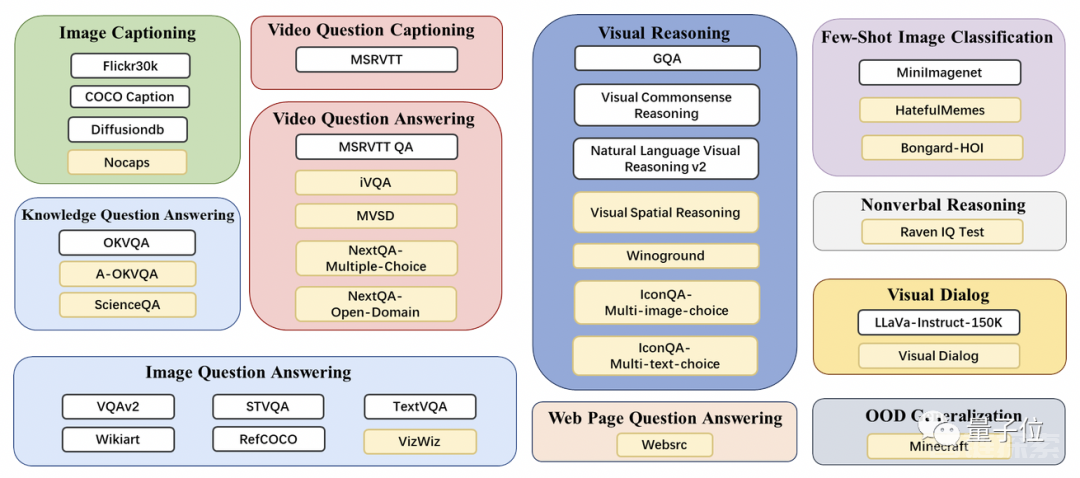
MIC数据集由公开数据集构建而来,上图展示了MIC数据集当中所包含的内容,而MIC数据集还具有这几个特色:
第一是图文间建立的显式指代,MIC在图文交错的数据中,插入图片声明(image declaration),使用图片代理(image proxy)token来代理不同的图片,利用自然语言来建立图文间的指代关系。

第二是空间,时间或逻辑上互相关联的多图数据集,确保了MMICL模型能对图像间的关系有更准确的理解。

第三个特色是示例数据集,类似于让MMICL“现场学习”的过程,使用多模态的上下文学习来增强MMICL对图文穿插式的复杂图文输入的理解。

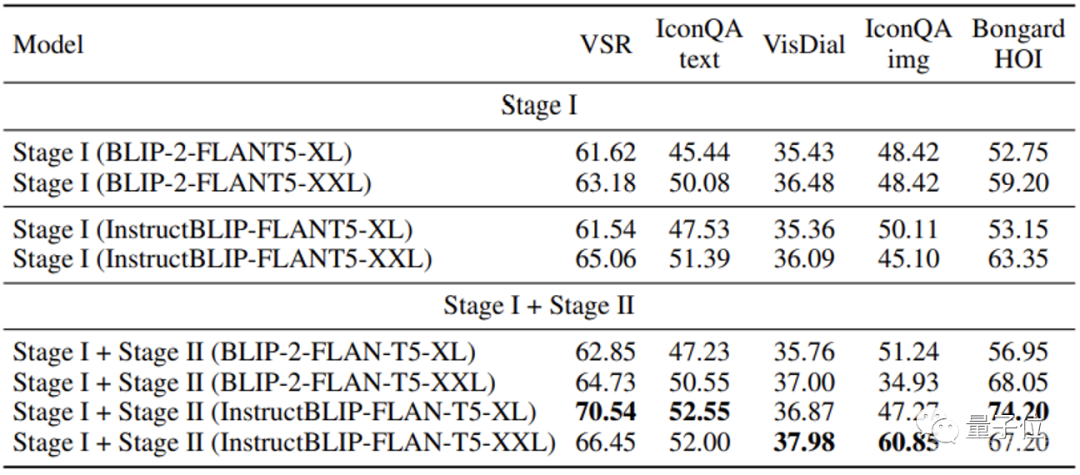
MMICL在多个测试数据集上取得的成绩超过了同样使用FlanT5XXL的BLIP2和InstructionBLIP。
尤其是对于涉及多张图的任务,对这种复杂图文输入,MMICL表现了极大的提升。
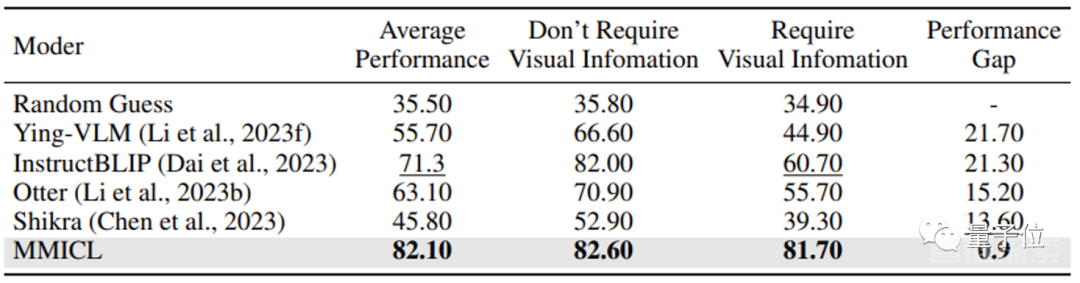
研究团队认为,MMICL解决了视觉语言模型中常常存在的语言偏见(language bais)问题是取得优异成绩的原因之一。
大多数视觉语言模型在面对大量文本的上下文内容时会忽视视觉内容,而这是回答需要视觉信息的问题时的致命缺陷。
而得益于研究团队的方法,MMICL成功缓解了在视觉语言模型中的这种语言偏见。
对这个多模态大模型感兴趣的读者,可以到GitHub页面或论文中查看更多详情。
GitHub页面:https://github.com/HaozheZhao/MIC
论文地址:https://arxiv.org/abs/2309.07915在线demo:
http://www.testmmicl.work/




还没有评论,来说两句吧...