

谷歌力推的JAX在最近的基准测试中性能已经超过Pytorch和TensorFlow,7项指标排名第一。

而且测试并不是在JAX性能表现最好的TPU上完成的。

虽然现在在开发者中,Pytorch依然比Tensorflow更受欢迎。
但未来,也许有更多的大模型会基于JAX平台进行训练和运行。
模型
最近,Keras团队为三个后端(TensorFlow、JAX、PyTorch)与原生PyTorch实现以及搭配TensorFlow的Keras 2进行了基准测试。
首先,他们为生成式和非生成式人工智能任务选择了一组主流的计算机视觉和自然语言处理模型:

对于模型的Keras版本,其采用了KerasCV和KerasNLP中已有的实现进行构建。而对于原生的PyTorch版本,则选择了网络上最流行的几个选项:
- 来自HuggingFace Transformers的BERT、Gemma、Mistral
- 来自HuggingFace Diffusers的StableDiffusion
- 来自Meta的SegmentAnything
他们将这组模型称作「Native PyTorch」,以便与使用PyTorch后端的Keras 3版本进行区分。
他们对所有基准测试都使用了合成数据,并在所有LLM训练和推理中使用了bfloat16精度,同时在所有LLM训练中使用了LoRA(微调)。
根据PyTorch团队的建议,他们在原生PyTorch实现中使用了torch.compile(model, mode="reduce-overhead")(由于不兼容,Gemma和Mistral训练除外)。
为了衡量开箱即用的性能,他们使用高级API(例如HuggingFace的Trainer()、标准PyTorch训练循环和Keras model.fit()),并尽可能减少配置。
硬件配置
所有基准测试均使用Google Cloud Compute Engine进行,配置为:一块拥有40GB显存的NVIDIA A100 GPU、12个虚拟CPU和85GB的主机内存。
基准测试结果
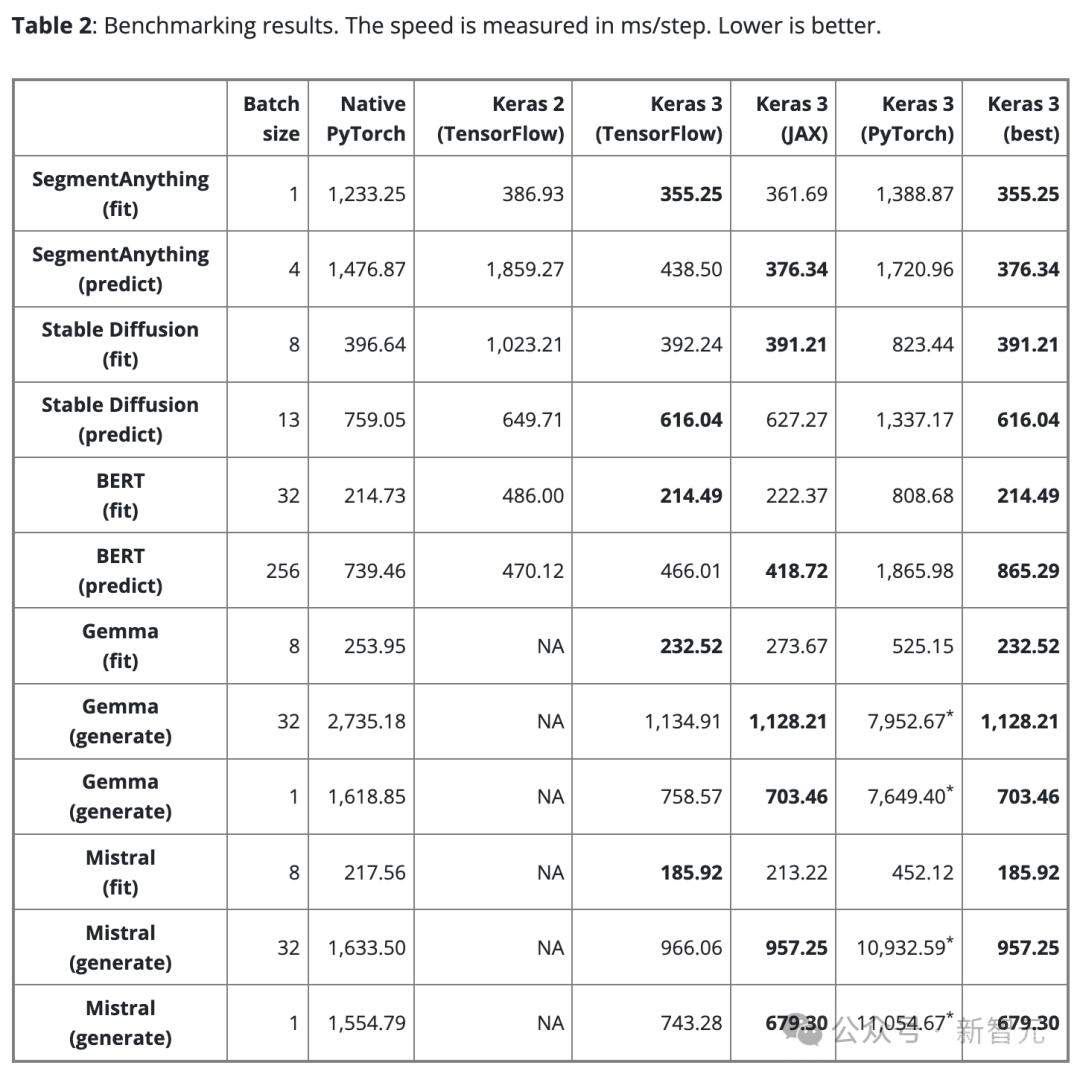
表2显示了基准测试结果(以步/毫秒为单位)。每步都涉及对单个数据批次进行训练或预测。
结果是100步的平均值,但排除了第一个步,因为第一步包括了模型创建和编译,这会额外花费时间。
为了确保比较的公平性,对于相同的模型和任务(不论是训练还是推理)都使用相同的批大小。
然而,对于不同的模型和任务,由于它们的规模和架构有所不同,可根据需要调整数据批大小,从而避免因过大而导致内存溢出,或是批过小而导致GPU使用不足。
过小的批大小也会使PyTorch看起来较慢,因为会增加Python的开销。
对于大型语言模型(Gemma和Mistral),测试时也使用了相同的批处理大小,因为它们是相同类型的模型,具有类似数量的参数(7B)。
考虑到用户对单批文本生成的需求,也对批大小为1的文本生成情况进行了基准测试。
关键发现
发现1
不存在「最优」后端。
Keras的三种后端各展所长,重要的是,就性能而言,并没有哪一个后端能够始终胜出。
选择哪个后端最快,往往取决于模型的架构。
这一点突出了选择不同框架以追求最佳性能的重要性。Keras 3可以帮助轻松切换后端,以便为模型找到最合适的选择。
发现2
Keras 3的性能普遍超过PyTorch的标准实现。
相对于原生PyTorch,Keras 3在吞吐量(步/毫秒)上有明显的提升。
特别是,在10个测试任务中,有5个的速度提升超过了50%。其中,最高更是达到了290%。
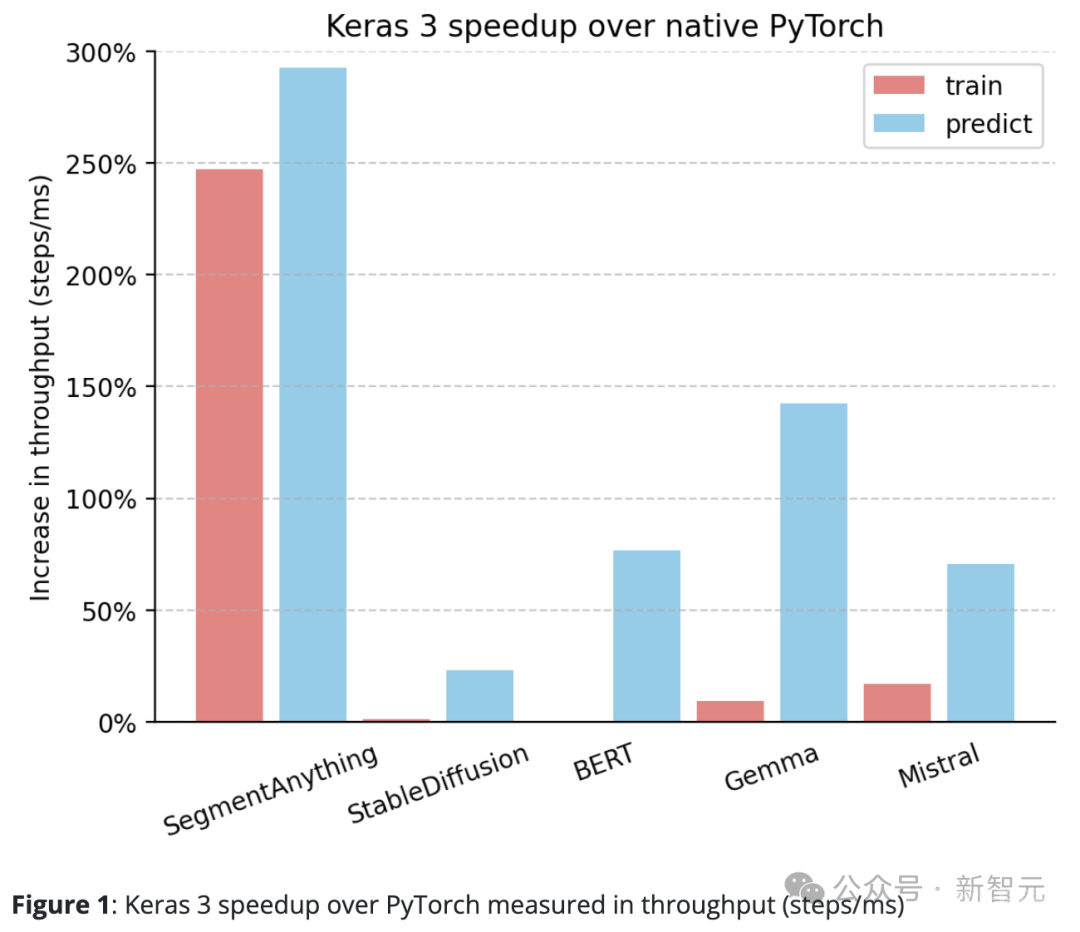
如果是100%,意味着Keras 3的速度是PyTorch的2倍;如果是0%,则表示两者性能相当
发现3
Keras 3提供一流的「开箱即用」性能。
也就是,所有参与测试的Keras模型都未进行过任何优化。相比之下,使用原生PyTorch实现时,通常需要用户自行进行更多性能优化。
除了上面分享的数据,测试中还注意到在HuggingFace Diffusers的StableDiffusion推理功能上,从版本0.25.0升级到0.3.0时,性能提升超过了100%。
同样,在HuggingFace Transformers中,Gemma从4.38.1版本升级至4.38.2版本也显著提高了性能。
这些性能的提升凸显了HuggingFace在性能优化方面的专注和努力。
对于一些手动优化较少的模型,如SegmentAnything,则使用了研究作者提供的实现。在这种情况下,与Keras相比,性能差距比大多数其他模型更大。
这表明,Keras能够提供卓越的开箱即用性能,用户无需深入了解所有优化技巧即可享受到快速的模型运行速度。
发现4
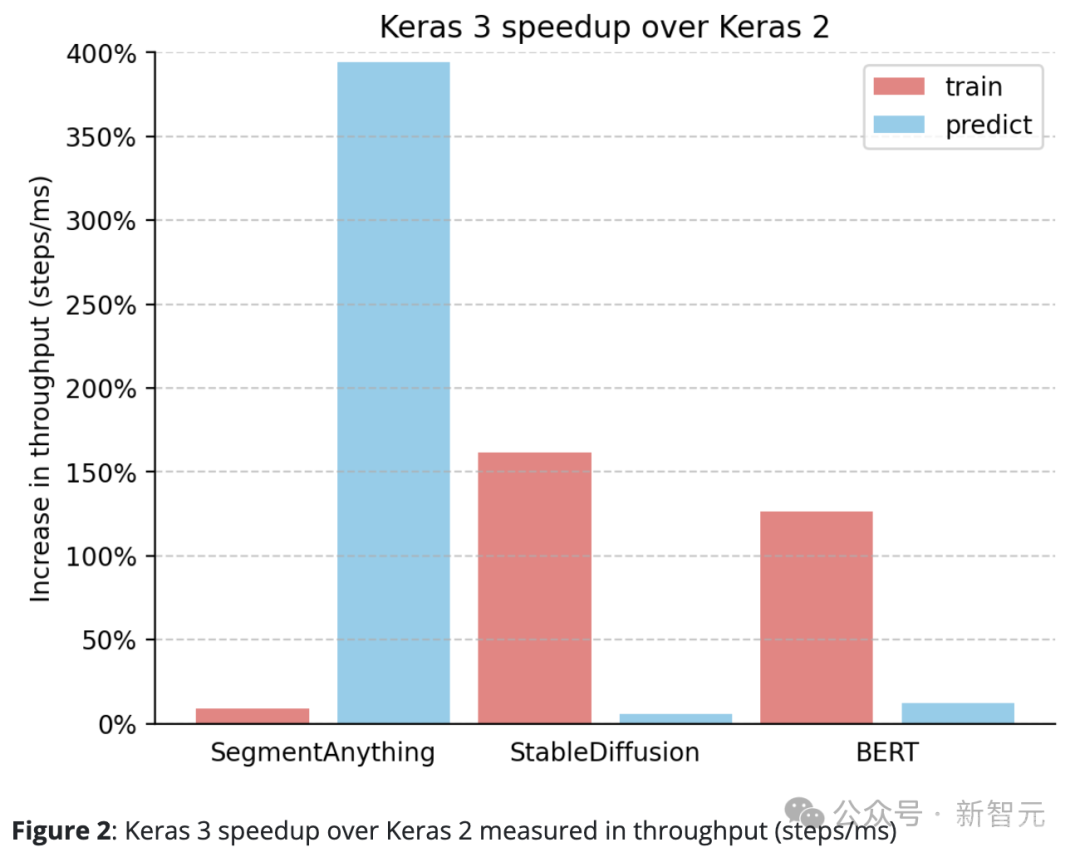
Keras 3的表现始终优于Keras 2。
例如,SegmentAnything的推理速度提升了惊人的380%,StableDiffusion的训练处理速度提升了150%以上,BERT的训练处理速度也提升了100%以上。
这主要是因为Keras 2在某些情况下直接使用了更多的TensorFlow融合操作,而这可能对于XLA的编译并不是最佳选择。
值得注意的是,即使仅升级到Keras 3并继续使用TensorFlow后端,也能显著提升性能。
结论
框架的性能在很大程度上取决于具体使用的模型。
Keras 3能够帮助为任务选择最快的框架,这种选择几乎总能超越Keras 2和PyTorch实现。
更为重要的是,Keras 3模型无需进行复杂的底层优化,即可提供卓越的开箱即用性能。




还没有评论,来说两句吧...