

作者 | 汪昊
审校 | 重楼
说到21 世纪互联网的技术,除了 Python / Rust / Go 等一系列新型编程语言的诞生,信息检索技术的蓬勃发展也是一大亮点。互联网上第一个纯技术商业模式就是以谷歌和百度为代表的搜索引擎技术。然而让大家臆想不到的是,推荐系统诞生的年代也很久远。早在1992 年,人类历史上第一个推荐系统就以论文的形式发表出来了,而在这个时候,谷歌和百度还没有诞生。

不像搜索引擎那样被人们认为是刚需,很快就诞生了许多独角兽。以推荐系统为核心技术的科技公司要等到2010 年代今日头条和抖音崛起后才会出现。毫无疑问,今日头条和抖音成为了推荐系统最成功的代表性公司。如果说第一代信息检索技术搜索引擎是美国人先发制人,那么第二代信息检索技术推荐系统就被牢牢的控制在中国人手里。而我们现在遇到了第三代信息检索技术—— 基于大语言模型的信息检索。目前来看先发者是欧美国家,但目前中美正在齐头并进。
近几年来,推荐系统领域的权威会议 RecSys 频频将最佳论文奖颁给序列推荐(Sequential Recommendation)。这说明该领域目前越来越重视垂直应用。而有一个推荐系统的垂直应用是如此重要,但至今都没有掀起滔天巨浪,这个领域就是基于场景的推荐(Context-aware Recommendation),简称CARS。我们偶尔会见到有些 CARS 的Workshop,但是这些Workshop 的论文每年不超过10 篇,门可罗雀。
CARS 可以用来干什么?首先CARS 已经被汉堡王等快餐公司使用。它还可以在用户驾驶汽车的时候,根据场景给用户推荐音乐。另外,我们可以畅想一下,我们有没有可能根据天气状况给用户推荐出行计划?抑或是根据用户的身体状况给用户推荐餐饮?其实,只要我们充分的发挥自己的想象力,总是能给CARS 找出不同的落地应用。
然而问题来了,既然CARS 的用途这么广泛,为什么这么少的人发表论文?原因很简单,因为CARS 几乎没有公开的数据集可以使用。目前最好用的 CARS 的公开数据集是来自斯洛文尼亚的LDOS-CoMoDa 数据集。除此之外,我们很难找到别的数据集合。LDOS-CoMoDa 利用调研的形式提供了用户观影时的场景数据,使得广大研究人员从事 CARS 研究成为了可能。数据公开的时间点在2012 年到2013 年左右,但是目前知道这个数据集合的人很少。
言归正传,本文主要介绍MatMat / MovieMat 算法和PowerMat 算法。这些算法都是用来解决 CARS 问题的利器。我们先来看一下MatMat 是如何定义CARS 问题的:我们首先重新定义用户评分矩阵,我们把用户评分矩阵的每一个评分值替换成方阵。方阵的对角线元素是原始的评分值,非对角线元素都是场景信息。
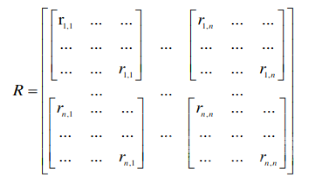
我们下面定义 MatMat 算法的损失函数,该函数修改了经典的矩阵分解损失函数,形式如下:
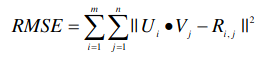
其中 U 和V 都是矩阵。我们通过这种方式,改变了原始的矩阵分解中的向量点乘。将向量点乘变成了矩阵乘法。我们举下面一个例子来看:
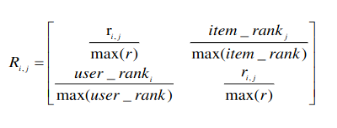
我们在MovieLens Small Dataset 上做一下性能对比实验,得到如下结果:
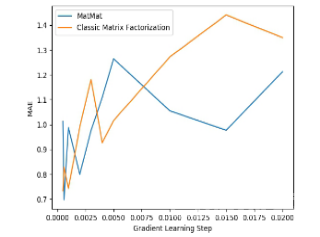
可以看到,MatMat 算法的效果优于经典的矩阵分解算法。我们再来检查一下推荐系统的公平性:

可以看到,MatMat 在公平性指标上表现依然不遑多让。MatMat 的求解过程较为复杂,即便是发明算法的作者本人,也没有在论文中写出推导过程。但是俗话说的好,学好线性代数,走遍天下都不怕。相信聪明的读者自己一定能推导出相关的公式,并实现这个算法。MatMat 算法论文的原文地址可以在下面的链接找到:https://arxiv.org/pdf/2112.03089.pdf 。这篇论文是国际学术会议IEEE ICISCAE 2021 最佳论文报告奖。
MatMat 算法被应用在了基于场景的电影推荐领域,该算法的电影实例被命名为MovieMat。MovieMat 的评分矩阵是按照如下方法定义的:
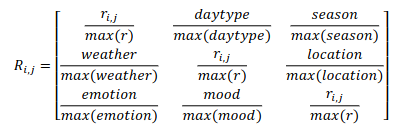
作者随后做了对比实验:
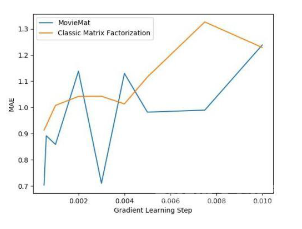
在LDOS-CoMoDa 数据集合上,MovieMat 取得了性能远高于经典矩阵分解的效果。下面我们来观察一下公平性的测评结果:
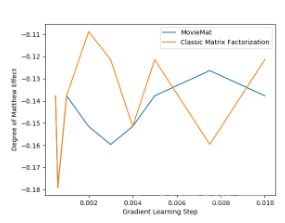
在公平性方面,经典矩阵分解取得了优于MovieMat 的结果。MovieMat 的原始论文可以在下面的链接找到:https://arxiv.org/pdf/2204.13003.pdf 。
我们有的时候会遇到这样的问题。我们新到了一个地点,光有场景数据,而没有用户评分数据该怎么办?不要紧,Ratidar Technologies LLC (北京达评奇智网络科技有限责任公司) 发明了基于零样本学习的 CARS 算法—— PowerMat。PowerMat 的原始论文可以在下面的链接找到:https://arxiv.org/pdf/2303.06356.pdf 。
PowerMat 的发明人借用了MAP 和DotMat,定义了如下的MAP 函数:
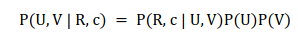
其中U 是用户特征向量、V 是物品特征向量、R 是用户评分值,而C 是场景变量。具体的,我们得到如下公式:
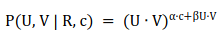
利用随机梯度下降对该问题进行求解,我们得到下述公式:
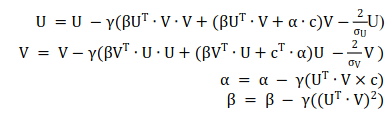
通过观察,我们发现在这组公式里没有出现任何输入数据相关的变量,因此 PowerMat 是仅与场景相关的零样本学习算法。该算法可以应用在如下场景:游客打算去某地旅游,但是从来没有去过当地,因此只有天气等场景数据,我们可以利用 PowerMat 给游客推荐打卡景点等等。
下面是PowerMat 和其他算法的对比数据:
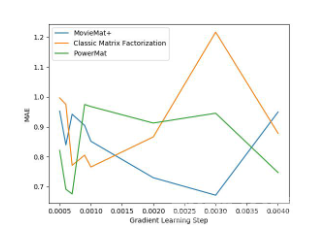
通过这张图,我们发现PowerMat 和MovieMat 旗鼓相当,不分伯仲,并且效果都要优于经典的矩阵分解算法。而下面这张图显示,即使是在公平性指标方面,PowerMat 依旧表现强劲:
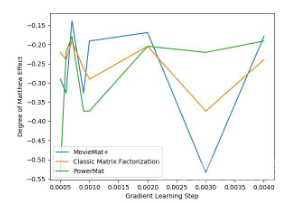
通过对比实验,我们发现PowerMat 是优秀的CARS 算法。
互联网的数据工程师经常说数据高于一切。并且在2010 年代左右互联网有一股强劲的看好数据看衰算法的风气。CARS 是个很好的例子。因为绝大多数人得不到相关数据,因此这个领域的发展一直受到了很大的限制。感谢斯洛文尼亚的研究人员公开了 LDOS-CoMoDa 数据集合,使得我们有机会发展这个领域。我们也希望有越来越多的人关注 CARS,落地 CARS,为 CARS 融资……
作者简介
汪昊,前Funplus 人工智能实验室负责人。曾在ThoughtWorks、豆瓣、百度、新浪等公司担任技术和技术高管职务。在互联网公司和金融科技、游戏等公司任职13 年,对于人工智能、计算机图形学和区块链等领域有着深刻的见解和丰富的经验。在国际学术会议和期刊发表论文42 篇,获得IEEE SMI 2008 最佳论文奖、ICBDT 2020 / IEEE ICISCAE 2021 / AIBT 2023 / ICSIM 2024 最佳论文报告奖。




还没有评论,来说两句吧...