

简介
大型语言模型已经证明自己是一项革命性的技术。目前,人们已经开发出了许多基于大型语言模型功能的应用程序,而且预计很快还会有更多的应用程序问世。大型语言模型最有趣的应用之一是将其部署为智能助手,它们能够帮助人类用户完成各种任务。
人们已经能够通过指令微调以及从人类的反馈中经强化学习训练出聊天模型,而且这些模型已经在遵循人类指令和执行指定任务方面表现出非常有前景的功能。然而,这些模型在仅凭语言指令执行任务方面表现出非常有限的适用性。
多模式会话模型旨在释放大型语言模型的力量,以解决需要将自然语言与其他模式相结合才能解决的问题。特别是,自从GPT-4V引入视觉功能以来,视觉语言模型受到了越来越多的关注。
通过图像理解增强GPT-4的自然语言功能,人们开发出了一款功能强大的聊天助手,可以帮助用户完成需要视觉和语言理解的任务。虽然GPT-4V的视觉能力令人印象深刻,但闭源模型限制了这项惊人技术的研究和实验潜力。幸运的是,已有一些开源模型以一种易于访问和透明的方式将视觉语言模型的力量带到了社区中。这些模型还延续了日益关注计算和内存效率的趋势,当然这也是开源大型语言模型已经出现的趋势。这是一个非常重要的特征,因为它促进了这些模型的广泛应用。
在本教程中,我将使用论文《可视化指令微调(Visual Instruction Tuning)》(https://arxiv.org/abs/2304.08485)中介绍的LLaVA(大型语言和视觉助手)模型来完成创建一个视觉聊天助手程序的过程。在讨论使用官方存储库(https://github.com/haotian-liu/LLaVA)中提供的代码实现视觉聊天助手的简单代码之前,我将首先简要介绍LLaVA模型及其改进。然后,我将展示一些我精心制作的示例,以展示该模型的功能和局限性。
LLaVA模型
LLaVA模型是在上述论文《可视化指令微调(Visual Instruction Tuning)》中引入的,然后在论文《基于可视化指令微调的基准改进(Improved Baselines with Visual Instruction Tuning)》(地址:https://arxiv.org/abs/2310.03744,也称为LLaVA-1.5模型)中得到进一步改进。其背后的思想是从图像中提取视觉嵌入,并通过将其馈送到大型语言模型,可将其视为来自语言标记的嵌入。直观地说,我们可以认为图像将会使用“单词”来描述——最初,这些单词是语言模型用来生成答案的。为了选择正确的“单词”,模型需要使用预先训练的CLIP视觉编码器来提取视觉嵌入,然后将它们投影到语言模型的单词嵌入空间中。后一种操作是用视觉语言连接器完成的,在第一篇论文《可视化指令微调》中,它最初被选择为一个简单的线性层,后来在论文《基于可视化指令微调的基准改进》中被一个更具表现力的多层感知器(MLP)所取代。该模型的体系结构如下所示:
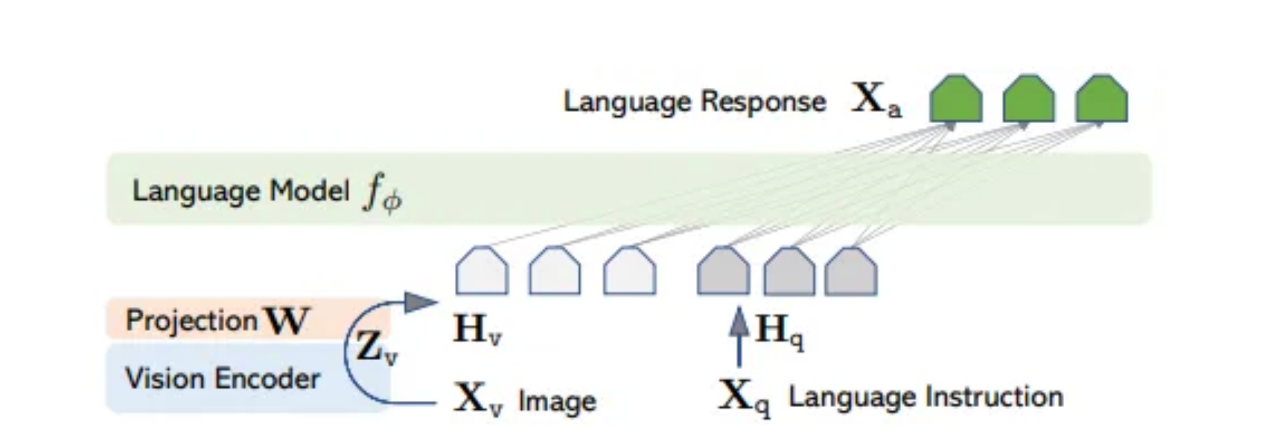
LLaVA模型的体系架构图
其中,投影W是LLaVA模型中的简单线性层或者是LLaVA-1.5模型中的MLP。本图像来自论文《可视化指令微调》。
该方法的优点之一是,通过引入预先训练的视觉编码器和预先训练的语言模型,只有视觉语言连接器(这是一个轻量级模块)必须从头开始学习,其他部分则不需要。特别是,LLava模型的训练仅包括两个阶段:
特征对齐的预训练:预训练的视觉编码器和语言模型都被冻结,并且只有视觉语言连接器的权重被更新。所有训练样本都由文本图像对组成,这些文本图像对被打包成单回合对话。该阶段旨在训练视觉语言连接器,使视觉编码器的嵌入与语言模型的文本嵌入对齐。
使用视觉指令进行微调:在这个阶段,只有视觉编码器的权重被固定,而视觉语言连接器和语言模型被微调在一起。该模型在基于图像的指令执行任务后进行了微调。值得注意的是,这些数据中的一些是通过仅使用GPT4语言创建的,以便根据图像的标题和所描绘的实体的边界框的坐标创建指令跟随样本。
视觉聊天机器人的实现
使用官方存储库(https://github.com/haotian-liu/LLaVA)中提供的代码创建视觉聊天机器人是相当容易的。另外,存储库还提供了标准化的聊天模板,可用于以正确的格式解析输入。遵循训练中使用的正确格式对于模型生成的答案的质量至关重要。当然,选择恰当的模板取决于所使用的语言模型。基于预先训练的Vicuna语言模型的LLaVA-1.5模型的模板如下所示:
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> User's prompt ASSISTANT: Assistant answer USER: Another prompt1.2.3.4.5.
前几行是模型使用的一般系统提示。后面的几个特殊标记<im_start>、<image>和<im_end>分别用于指示表示图像的嵌入将被放置的位置。
然后,聊天机器人可以在一个简单的Python类中定义。
class LLaVAChatBot: def __init__(self, model_path: str = 'liuhaotian/llava-v1.5-7b', device_map: str = 'auto', load_in_8_bit: bool = True, **quant_kwargs) -> None: self.model = None self.tokenizer = None self.image_processor = None self.conv = None self.conv_img = None self.img_tensor = None self.roles = None self.stop_key = None self.load_models(model_path, device_map=device_map, load_in_8_bit=load_in_8_bit, **quant_kwargs) def load_models(self, model_path: str, device_map: str, load_in_8_bit: bool, **quant_kwargs) -> None: """Load the model, processor and tokenizer.""" quant_cfg = BitsAndBytesConfig(**quant_kwargs) self.model = LlavaLlamaForCausalLM.from_pretrained(model_path, low_cpu_mem_usage=True, device_map=device_map, load_in_8bit=load_in_8_bit, quantization_config=quant_cfg) self.tokenizer = AutoTokenizer.from_pretrained(model_path, use_fast=False) vision_tower = self.model.get_vision_tower() vision_tower.load_model() vision_tower.to(device='cuda') self.image_processor = vision_tower.image_processor disable_torch_init() def setup_image(self, img_path: str) -> None: """Load and process the image.""" if img_path.startswith('http') or img_path.startswith('https'): response = requests.get(img_path) self.conv_img = Image.open(BytesIO(response.content)).convert('RGB') else: self.conv_img = Image.open(img_path).convert('RGB') self.img_tensor = self.image_processor.preprocess(self.conv_img, return_tensors='pt' )['pixel_values'].half().cuda() def generate_answer(self, **kwargs) -> str: """Generate an answer from the current conversation.""" raw_prompt = self.conv.get_prompt() input_ids = tokenizer_image_token(raw_prompt, self.tokenizer, IMAGE_TOKEN_INDEX, return_tensors='pt').unsqueeze(0).cuda() stopping = KeywordsStoppingCriteria([self.stop_key], self.tokenizer, input_ids) with torch.inference_mode(): output_ids = self.model.generate(input_ids, images=self.img_tensor, stopping_criteria=[stopping], **kwargs) outputs = self.tokenizer.decode( output_ids[0, input_ids.shape[1]:] ).strip() self.conv.messages[-1][-1] = outputs return outputs.rsplit('</s>', 1)[0] def get_conv_text(self) -> str: """Return full conversation text.""" return self.conv.get_prompt() def start_new_chat(self, img_path: str, prompt: str, do_sample=True, temperature=0.2, max_new_tokens=1024, use_cache=True, **kwargs) -> str: """Start a new chat with a new image.""" conv_mode = "v1" self.setup_image(img_path) self.conv = conv_templates[conv_mode].copy() self.roles = self.conv.roles first_input = (DEFAULT_IM_START_TOKEN + DEFAULT_IMAGE_TOKEN + DEFAULT_IM_END_TOKEN + '\n' + prompt) # f"{self.roles[0]}: {prompt}") self.conv.append_message(self.roles[0], first_input) self.conv.append_message(self.roles[1], None) if self.conv.sep_style == SeparatorStyle.TWO: self.stop_key = self.conv.sep2 else: self.stop_key = self.conv.sep answer = self.generate_answer(do_sample=do_sample, temperature=temperature, max_new_tokens=max_new_tokens, use_cache=use_cache, **kwargs) return answer def continue_chat(self, prompt: str, do_sample=True, temperature=0.2, max_new_tokens=1024, use_cache=True, **kwargs) -> str: """Continue the existing chat.""" if self.conv is None: raise RuntimeError("No existing conversation found. Start a new" "conversation using the `start_new_chat` method.") self.conv.append_message(self.roles[0], prompt) self.conv.append_message(self.roles[1], None) answer = self.generate_answer(do_sample=do_sample, temperature=temperature, max_new_tokens=max_new_tokens, use_cache=use_cache, **kwargs) return answer1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.65.66.67.68.69.70.71.72.73.74.75.76.77.78.79.80.81.82.83.84.85.86.87.88.89.90.91.92.93.94.95.96.97.98.99.100.101.102.103.104.105.106.107.108.109.110.111.112.113.114.115.116.117.118.119.120.121.122.如果你熟悉Transformers库(https://github.com/huggingface/transformers)的话,你会认识其中许多常见的功能,并且执行的操作应该也很容易理解。让我们快速回顾一下上面定义的LLaVAChatBot类的方法。
load_models:此方法使用指定的参数加载语言模型、标记器和图像处理器,以便使用BitsAndBytes库进行量化。该代码隐藏了“Hugging Face”转换器模型使用的from_pretrained方法。BitsAndBytes允许量化为8位或4位,以减少GPU内存需求。
setup_image:这个方法实现从本地路径或URL加载图像,并使用图像处理器将其转换为张量。
generate_answer:此方法返回模型的答案,继续当前关于所提供图像的对话。LLaVa模型的生成方法类似于Hugging Face转换模型的生成方式。
get_conv_text:此方法返回到目前为止对话的原始文本。
start_new_chat:这是聊天机器人的两种主要方法之一,用于与模型开始新的聊天。它在给定图像和传递给模型的初始提示的情况下创建一个新的对话。它按照上一节中讨论的格式,使用存储库中定义的模板来设置对话。
continue_chat:这是另一个主要方法,它负责继续关于图像的现有对话。
我已经在Colab笔记本(https://colab.research.google.com/drive/1tq9K3utBJ4VeMmuUarMEFCmaekMUG_Zd?usp=sharing)中提供了完整的代码,所以感兴趣的读者可以自己尝试一下。
测试示例
在本节中,我收集了一些在测试模型功能时获得的有趣示例。本文中的所有示例都是使用具有8位量化的模型llava-v1.5–7b模型创建的。
首先,让我们看看模型描述和其理解图像的能力。下面我请模型描述一张白虎的照片。

Joshua J. Cotten在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> Describe the image in details. ASSISTANT: The image features a white tiger laying down on a rocky surface, possibly a stone wall or a rock. The tiger appears to be relaxed and comfortable in its environment. The tiger's position is such that it covers a significant portion of the image, from the left side to almost the entire right side. The rocky surface provides a natural and rugged backdrop for the scene.</s></s> USER: What is unique about this tiger? ASSISTANT: This tiger is unique because it is a white tiger, which is an extremely rare and visually striking variation of the species. White tigers are born with a genetic mutation that causes their fur to be predominantly white, with the rest of their body being a mix of orange and black stripes. This distinctive appearance sets them apart from the more common orange and black striped tigers.</s></s>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.
该模型似乎能够详细描述图像,也能够推理图像的主题,正确地评估白虎还是非常罕见的。
接下来,我测试了该模型是否能够为用户提供执行各种任务的可操作指令。这就是“字幕”模式与真正的视觉聊天助手的区别。例如,模型能否根据图像中的成分提供食谱呢?结果报告如下:

ThermoPro在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> What can I cook with these ingredients? ASSISTANT: With the ingredients displayed on the table, you can prepare a delicious roast dinner. The meat, which is a large piece of beef, can be seasoned and cooked in the oven, while the vegetables, including carrots, potatoes, and onions, can be roasted alongside the meat. You can also prepare a side dish with the potatoes, carrots, and onions, which can be served alongside the roast dinner. The presence of a bowl of sauce suggests that you can use it as a dipping sauce or to enhance the flavors of the roast and vegetables. Overall, this combination of ingredients offers a hearty and flavorful meal that can be enjoyed with family and friends.</s></s> USER: Could the recipe you suggested be included in a vegetarian diet? ASSISTANT: The recipe I suggested, which involves roasting a large piece of beef and vegetables, is not suitable for a vegetarian diet. The beef is the main protein source in the dish, and it is not suitable for vegetarians who avoid consuming meat. However, you can still create a vegetarian-friendly meal using the vegetables and sauce availableon the table. For example, you can prepare a vegetable roast with the carrots, potatoes, and onions, and serve it alongside a side of mashed potatoes or a vegetable-based sauce. This way, you can still enjoy the flavors and textures of the dish without including meat.</s></s> USER: Can you suggest a vegetarian recipe with minimal modifications of the depicted ingredients? ASSISTANT: Certainly! Here's a vegetarian recipe that can be made using the ingredients available on the table: Roasted Vegetable Medley with Sauce Ingredients: * Carrots * Potatoes * Onions * Olive oil * Salt * Pepper * Herbs (such as thyme, rosemary, or parsley) * Sauce (optional) Instructions: 1. Preheat your oven to 400°F (200°C). 2. Wash and peel the carrots, potatoes, and onions. Cut them into bite-sized pieces. 3. In a large bowl, toss the vegetables with olive oil, salt, and pepper. 4. Spread the vegetables evenly on a baking sheet lined with parchment paper. 5. Roast the vegetables in the preheated oven for 20-25 minutes, or until they are tender and slightly browned. 6. If desired, prepare a sauce by combining ingredients such as tomatoes, garlic, and herbs. You can use this sauce as a dipping sauce or to enhance the flavors of the roasted vegetables. 7. Serve the roasted vegetable medley alongside a side of mashed potatoes or a vegetable-based sauce. This vegetarian recipe allows you to enjoy the flavors and textures of the roasted vegetables without including meat. The sauce can be easily customized to suit your taste preferences, and the dish can be served alongside a variety of side dishes, such as mashed potatoes or a vegetable-based sauce.</s></s>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.45.46.47.48.49.50.51.52.53.54.55.56.57.58.59.60.61.62.63.64.
该模型似乎对图像中的成分有很好的理解,并且能够将单个单词与更抽象的概念联系起来(即,有肉的饭不是素食)。
现在,让我们看看如何使用该模型来获得建议。这是一个在头脑风暴时获得新想法的有用功能,可以为用户提供真正的价值。在下面的对话中,我向模型征求了改变咖啡馆外观的建议。

MichałMancewicz在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> How can I renovate this café to make it look more vintage? ASSISTANT: To make the café look more vintage, you can consider the following changes: 1. Update the lighting: Replace the current lighting with vintage-style lamps or lanterns, which will create a warm and cozy atmosphere. 2. Add vintage decorations: Incorporate antique items, such as vintage clocks, artwork, or decorative plates, to create a nostalgic ambiance. 3. Use vintage furniture: Replace the current stools with vintage-style chairs or barstools, which can add character and charm to the space. 4. Incorporate greenery: Add more greenery, such as potted plants or vines, to create a lush and inviting atmosphere. 5. Update the bar: Replace the current bar with a vintage-style bar, complete with a vintage-inspired backsplash and countertop. 6. Use vintage-style glassware: Replace the current glassware with vintage-style glasses, such as wine glasses, beer mugs, or cocktail shakers. 7. Add vintage-style signage: Replace the current signage with vintage-style menu boards or chalkboards, which can add a touch of nostalgia to the space. 8. Use vintage-style wallpaper or paint: Apply a vintage-style wallpaper or paint to the walls, which can create a unique and charming atmosphere. By implementing these changes, the café will appear more vintage and inviting, creating a memorable experience for its patrons.</s></s>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.
该建议看起来很中肯,尽管相当笼统,但确定了当前可以改变的元素,以赋予更复古的风格。
让我们继续探讨一些能够帮助用户完成日常活动的实用的内容。该模型可以帮助撰写广告或列表吗?

Eugene Chystiakov在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> Write an advertisment for this chair ASSISTANT: Introducing the modern and stylish black and wood chair, perfect for any contemporary setting. This chair features a sleek black seat and a wooden base, creating a striking contrast against any background. Its minimalist design makes it a versatile addition to any room, whether it's used as a dining chair, a side table, or a statement piece in a living space. The chair's sturdy construction ensures it can withstand daily use, while its clean lines and sleek appearance add a touch of sophistication to any room. Upgrade your living space with this stylish and functional chair today.</s></s> USER: Write now an advertisement for the same chair but targeting cafes ASSISTANT: Attention café owners and design enthusiasts! Introducing the black and wood chair, the perfect addition to your café's seating area. This stylish and functional chair offers a modern touch to your establishment, with its sleek black seat and wooden base creating a striking contrast against any background. Its minimalist design makes it a versatile choice for any café setting, whether it's used as a dining chair, a side table, or a statement piece in a lounge area. The chair's sturdy construction ensures it can withstand daily use, while its clean lines and sleek appearance add a touch of sophistication to any room. Upgrade your café's ambiance with this stylish and functional chair today.</s></s>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.
该模型能够正确地定位椅子的特征,并创建一个有吸引力的广告,而且可以根据要求并针对不同的目标正确地定制答案。
作为最后一个测试,让我们看看已经证明对大型语言模型有益的提示技术是否也可以与LLaVA模型一起使用。下面是一个尝试使用零样本思维链提示的例子。

Arnold Middelkoop在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> Would the fish depicted in the image float if thrown in water? Think step by step. ASSISTANT: The fish depicted in the image is a large white fish sculpture or statue, which is lying on the ground on a brick walkway near a body of water. If thrown into the water, the fish would not float because it is a solid, inanimate object. It would sink to the bottom of the water, as it is not buoyant due to its composition and size. The fish's position on the ground and its lack of buoyancy make it impossible for it to float in water.</s></s> USER: What material could be used to make a fish sculpture that floats on water? ASSISTANT: To make a fish sculpture that floats on water, one could use a lightweight, buoyant material such as expanded polystyrene foam or polyethylene foam. These materials are commonly used for making buoyant objects like life jackets, flotation devices, and fishing floats. By shaping the foam into the desired fish form, it would be able to float on the water's surface, simulating the behavior of a real fish.</s></s>1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.
该模型能够解释为什么鱼不会漂浮,正确地识别出它不是真正的鱼。此外,模型还遵循指示,在给出最终答案之前循序渐进地思考。为了进行比较,下面给出一个没有“一步一步思考(Think step by step)”提示的对话示例。
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> Would the fish depicted in the image float if thrown in water? ASSISTANT: No, the fish depicted in the image would not float if thrown in water. It is a large, white, stone fish sculpture, which is not a real fish and does not have the buoyancy properties of a natural fish.</s></s>1.2.3.4.5.6.7.8.9.
虽然最后的答案仍然是正确的,但在这种情况下给出的解释要详细得多,答案是在句子的开头给出的。由于LLaVA使用的生成语言模型是因果关系的,这意味着所提供的答案不依赖于随后的解释。进行更广泛的实验来测试思维链(CoT)是否能够在复杂的推理任务中提高视觉语言模型的性能是一件有趣的事情,这非常类似于在论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models 》(https://arxiv.org/abs/2201.11903)和《Large Language Models are Zero-Shot Reasoners》(https://arxiv.org/abs/2205.11916)中观测的大型语言模型。
局限性
LLaVA模型的功能虽然非常强大,但也有其局限性。例如,该模型已被训练为每次聊天只使用一个图像,因此它无法处理需要与多个图像交互的更复杂的对话。这种限制并不是模型架构固有的,可以通过在训练期间包括多图像聊天数据来进行修改。
在测试过程中,我注意到该模型(至少是1.57b模型的8位量化版本)在计算图像中的元素以及处理数字任务方面存在问题。下面是一个例子。

John Matychuk在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> How many car are inside the parking lot? ASSISTANT: There are several cars parked inside the parking lot.</s></s> USER: List the numbers of the parking spots occupied by cars ASSISTANT: The parking spots occupied by cars are 66, 67, 68, 69, 70, and 71.</s></s>1.2.3.4.5.6.7.8.9.10.11.
与所有大型语言模型一样,该模型也容易产生“幻觉”,使用适当的提示很容易出错。例如,如果提供一张沙漠的照片,并询问图像中的鱼是什么物种,就会产生沙漠鱼的幻觉。

Wolfgang Hasselmann在Unsplash上拍摄的照片
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: <im_start><image><im_end> Tell me the species of the fish in this image ASSISTANT: The fish in this image is a desert fish, which is a species adapted to living in desert environments.</s></s>1.2.3.4.5.6.7.8.
结论
总之,LLaVA模型已经在视觉语言理解方面表现出令人印象深刻的能力。它标志着多模式开源视觉语言模型向前迈出了明确的一步。LLaVA模型最大的优点之一是它是轻量级的,易于训练和微调。例如,LLaVA 1.5 13b的完整训练只需要120万个数据,在单个8-A100节点上大约需要1天时间。这使得它适合在特定领域进行微调,来担当一个专家助理——正如在论文《LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day》(LLaVA Med:在一天内为生物医学训练大型语言和视觉助理)((https://arxiv.org/abs/2306.00890))中所做的那样。
在聊天助手中添加视觉功能扩展了此类模型的应用领域,将其革命性的潜力带到了更复杂、更细致的任务中。将图像特征视为语言标记也带来了使用纯文本语言模型中使用的所有高级提示技术的可能性,并作出进一步的扩展。例如,可以通过检索与对话相关的文本和图像来扩展检索增强生成的功能。事实上,使用CLIP的共享图像-文本嵌入空间,可以从输入文本或图片开始检索外部文档和外部图像!
论文《LLaVA Interactive:An All-in-One Demo for Image Chat,Segmentation,Generation and Editing》(https://arxiv.org/abs/2311.00571)中介绍了扩展该模型功能的另一个有趣方向。其主要思想是将视觉语言聊天模型、文本到图像生成模型和其他视觉模型(如图像分割模型)的各种功能相结合,以获得能够处理多模式输入和生成多模式输出的助手。
总之,LLaVA模型标志着开源多模态生成模型迈出了重要的一步,这些模型表现出了令人印象深刻的能力,并吸引了很多人的兴趣。随着开源模型的广泛采用,我相信我们很快就会看到基于这些强大模型的新应用程序迅速增加。
最后,感谢你的阅读!如果你想自己试用一下代码,你可以看看这个Colab笔记本(https://colab.research.google.com/drive/1tq9K3utBJ4VeMmuUarMEFCmaekMUG_Zd?usp=sharing)。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。
原文标题:Create your Vision Chat Assistant with LLaVA,作者:Gabriele Sgroi
链接:https://towardsdatascience.com/create-your-vision-chat-assistant-with-llava-610b02c3283e。




还没有评论,来说两句吧...