

强化学习是一种机器学习的方法,它通过让智能体(Agent)与环境交互,从而学习如何选择最优的行动来最大化累积的奖励。强化学习在许多领域都有广泛的应用,例如游戏、机器人、自动驾驶等。强化学习也可以用于干预人类的行为,帮助人类实现他们的长期目标,例如戒烟、减肥、健身等。这些任务通常是摩擦性的,也就是说,它们需要人类付出长期的努力,而不是立即获得满足。在这些任务中,人类往往表现出有限的理性,也就是说他们的行为并不总是符合他们的最佳利益,而是受到一些认知偏差、情绪影响、环境干扰等因素的影响。因此,如何用强化学习干预人类的有限理性,使其在摩擦性的任务中表现更好,是一个具有重要意义和挑战性的问题。
为了解决这个问题,一篇最近发表在AAMAS2024会议上的论文《Reinforcement Learning Interventions on Boundedly Rational Human Agents in Frictionful Tasks》提出了一种行为模型强化学习(BMRL)的框架,用于让人工智能干预人类在摩擦性任务中的行为。该论文的作者是来自哈佛大学、剑桥大学和密歇根大学的五位研究人员,他们分别是Eura Nofshin、Siddharth Swaroop、Weiwei Pan、Susan Murphy和Finale Doshi-Velez。他们的研究受到了Simons Foundation、National Science Foundation、National Institute of Biomedical Imaging and Bioengineering等机构的资助。他们的论文的主要贡献有以下几点:
1)他们提出了一种新的Agent模型,称为链世界(ChainWorld),用于描述Agent在摩擦性任务中的行为。链世界是一种简单的马尔可夫决策过程(MDP)模型,其中Agent可以选择执行或跳过任务,从而增加或减少他们达到目标的概率。人工智能可以通过改变Agent的折扣因子或奖励来影响人类的决策。链世界的优点是它可以快速地对人类进行个性化,也可以解释人类的行为背后的原因。
2)他们引入了一种基于BMRL的Agent模型之间的等价性的概念,用于判断不同的Agent模型是否会导致相同的人工智能干预策略。他们证明了链世界是一类更复杂的人类MDP的等价模型,只要它们导致相同的三窗口人工智能策略,即由无效窗口、干预窗口和无需干预窗口组成的策略。他们还给出了一些与链世界等价的更复杂的人类MDP的例子,例如单调链世界、进展世界和多链世界,这些模型可以捕捉一些与人类行为相关的有意义的特征。
3)他们通过实验分析了链世界的鲁棒性,即当真实的Agent模型与链世界不完全匹配或不等价时,人工智能使用链世界进行干预的性能如何。他们发现链世界是一种有效且鲁棒的Agent模型,可以用于设计人工智能干预策略,在大多数情况下,它可以达到或接近最佳的性能,即使在一些极端的情况下,它也可以保持一定的水平。
我们将对这篇论文的主要内容进行更详细的解读和分析,从而帮助您更好地理解和评价这项研究的质量和意义。
首先,我们来看看什么是行为模型强化学习(BMRL)的框架,以及为什么它是一种适合用于干预人类行为的方法。BMRL是一种基于模型的强化学习的方法,它假设人工智能可以观察到人类的状态、行动和奖励,从而建立一个Agent的MDP模型。Agent的MDP模型由一组状态、一组行动、一个转移函数、一个奖励函数和一个折扣因子组成。Agent的目标是通过选择最优的行动来最大化他们的期望累积奖励。然而Agent的MDP模型可能存在一些问题,导致Agent的行为与他们的目标不一致,例如:
人类的折扣因子可能过低,导致人类过于看重短期的奖励,而忽视长期的后果。例如,一个想要戒烟的人可能会因为一时的瘾而放弃他的计划。
人类的奖励函数可能存在一些摩擦,导致人类执行任务的成本过高,而收益过低。例如,一个想要减肥的人可能会因为运动的痛苦而不愿意坚持他的计划。
人类的转移函数可能存在一些不确定性,导致人类执行任务的结果难以预测,而风险过高。例如,一个想要学习一门新语言的人可能会因为学习的难度而不敢尝试他的计划。
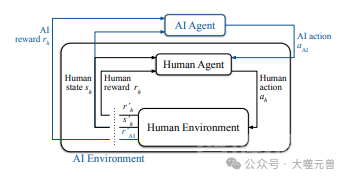
图1:BMRL概述,人类代理与环境交互,如标准RL中所示。人工智能主体的行为会影响人类主体。人工智能环境由人工智能主体+环境构成。
在这些情况下,人工智能可以通过干预人类的MDP模型的参数,来改变人类的行为,使其更接近他们的目标。例如,人工智能可以通过以下方式来干预人类的行为。
一是通过提供一些正向的反馈或奖励,来提高人类的折扣因子,从而增强人类对长期目标的关注。例如,人工智能可以通过发送一些鼓励的信息或提供一些小礼物,来激励一个想要戒烟的人坚持他的计划。
二是通过提供一些便利的工具或服务,来降低人类执行任务的成本,从而增加人类的收益。例如,人工智能可以通过提供一些个性化的运动计划或设备,来帮助一个想要减肥的人坚持他的计划。
三是通过提供一些有用的信息或建议,来降低人类执行任务的不确定性,从而减少人类的风险。例如,人工智能可以通过提供一些有效的学~~~
接下来,我们来看看什么是链世界(ChainWorld),以及为什么它是一种简单而有效的人类模型。链世界是一种由作者提出的人类MDP模型,它可以用来描述人类在摩擦性任务中的行为。
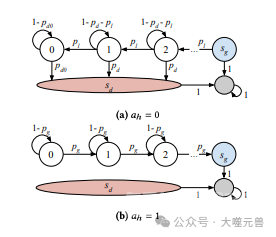 图2:链世界的图形表示。
图2:链世界的图形表示。
链世界的基本结构如下:
链世界由𝑁个状态组成,每个状态对应于人类执行任务的进度。状态𝑠0表示人类刚开始执行任务,状态𝑠𝑁−1表示人类即将完成任务,状态𝑠𝑁表示人类已经完成任务,也就是达到了他们的长期目标。状态𝑠𝑑表示人类放弃了任务,也就是与他们的长期目标背道而驰。
链世界有两个行动,𝑎=1表示人类执行任务,𝑎=0表示人类跳过任务。当人类执行任务时,他们有一定的概率𝑝𝑔增加进度,也有一定的概率𝑝ℓ减少进度。当人类跳过任务时,他们有一定的概率𝑝𝑑放弃任务,也有一定的概率1−𝑝𝑑保持进度不变。人类的行动选择取决于他们的折扣因子𝛾ℎ和奖励函数𝑟。
链世界的奖励函数𝑟由四个参数组成,分别是𝑟𝑔、𝑟𝑑、𝑟𝑏和𝑟ℓ。𝑟𝑔表示人类完成任务的奖励,𝑟𝑑表示人类放弃任务的奖励,𝑟𝑏表示人类执行任务的成本,𝑟ℓ表示人类减少进度的惩罚。人类的奖励函数反映了他们对任务的价值和摩擦的感受。
链世界的折扣因子𝛾ℎ表示人类对未来奖励的重视程度,它决定了人类的行为是否与他们的长期目标一致。人类的折扣因子可能受到一些因素的影响,例如情绪、注意力、自我控制等。人类的折扣因子反映了他们的有限理性和认知偏差。
 图片
图片
图3:具有不同链世界参数的两个人的不同最优人工智能策略示例。每个方块都是一个链世界状态。一𝑎𝑏意味着AI应该选择行动来减少𝑟𝑏,虽然𝑎𝛾意味着AI应该选择行动来增加𝛾. 红色实线和蓝色虚线显示干预窗口的开始和结束。
链世界的优点是它可以用少量的参数来描述人类在摩擦性任务中的行为,从而使人工智能可以快速地对人类进行个性化。人工智能可以通过观察人类的状态、行动和奖励,来估计人类的MDP模型的参数,然后根据人类的MDP模型来选择最优的干预策略。人工智能的干预策略可以通过改变人类的折扣因子或奖励来实现,从而影响人类的行为选择。例如,人工智能可以通过提供一些正向的反馈或奖励,来提高人类的折扣因子,从而增强人类对长期目标的关注。人工智能也可以通过提供一些便利的工具或服务,来降低人类执行任务的成本,从而增加人类的收益。
链世界的另一个优点是它可以解释人类的行为背后的原因,从而使人工智能可以与人类进行有效的沟通和合作。人工智能可以通过分析人类的MDP模型的参数,来了解人类的行为动机、偏好、障碍和困难。人工智能也可以通过向人类提供一些有用的信息或建议,来帮助人类理解他们的行为后果、风险和机会。人工智能还可以通过向人类展示他们的MDP模型的参数,来促进人类的自我反思和自我调节。人工智能的这些功能可以增加人类对人工智能的信任和接受度,从而提高人工智能干预的效果和满意度。
我们来看看作者是如何证明链世界的最优人工智能策略具有三窗口的形式,以及这种形式的意义和优势。作者首先给出了链世界的最优人工智能策略的定义,即在每个状态下,选择能够使人类的期望累积奖励最大化的干预策略。作者然后利用动态规划的方法,推导出了链世界的最优人工智能策略的递推公式,即在每个状态下,比较人工智能干预和不干预的两种情况下,人类的期望累积奖励的大小,选择较大的一种作为最优的干预策略。作者接着证明了链世界的最优人工智能策略具有三窗口的形式,即存在三个临界状态𝑠𝑙、𝑠𝑚和𝑠𝑢,使得在𝑠𝑙之前,人工智能不干预;在𝑠𝑙和𝑠𝑚之间,人工智能干预折扣因子;在𝑠𝑚和𝑠𝑢之间,人工智能干预奖励;在𝑠𝑢之后,人工智能不干预。作者还给出了三个临界状态的计算方法,即通过求解一些不等式和方程,得到𝑠𝑙、𝑠𝑚和𝑠𝑢的值。
链世界的最优人工智能策略的三窗口形式有三个意义和优势。
它可以解释人类在摩擦性任务中的行为模式,即人类在任务的开始和结束阶段,往往不需要人工智能的干预,而在任务的中间阶段,往往需要人工智能的干预。这是因为在任务的开始阶段,人类的动机和信心往往较高,而在任务的结束阶段,人类的目标和收益往往较明确,因此人类的行为与他们的长期目标较为一致。而在任务的中间阶段,人类的动机和信心往往较低,而且目标和收益往往较模糊,因此人类的行为与他们的长期目标较为偏离。因此,人工智能的干预可以在适当的时机,提高人类的折扣因子或奖励,从而增强人类的行为一致性。
它可以指导人工智能的干预设计,即人工智能可以根据人类的状态,选择合适的干预方式,从而提高干预的效率和效果。例如,人工智能可以根据人类的进度,选择干预折扣因子或奖励,从而影响人类的行为选择。人工智能也可以根据人类的折扣因子或奖励的变化量,选择合适的干预强度,从而平衡干预的成本和收益。人工智能还可以根据人类的反馈,调整干预的策略,从而适应人类的个性和偏好。
它可以作为人类模型的等价性的判据,即人工智能可以通过比较不同的人类模型是否导致相同的三窗口人工智能策略,来判断它们是否等价。这样,人工智能可以使用链世界作为其他人类MDP的替代模型,而不会损失性能。这样,人工智能可以减少人类模型的复杂度和不确定性,从而提高干预的可解释性和可信度。
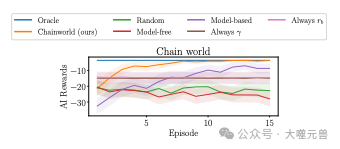
图4:当真正的人类模型是一个链世界时,我们的方法会迅速个性化。情节是多集(x轴)的AI奖励(y轴)。左上角的线条更具个性。
最后,我们来看看作者是如何通过实验分析链世界的鲁棒性,即当真实的人类模型与链世界不完全匹配或不等价时,人工智能使用链世界进行干预的性能如何。作者设计了一系列的实验,来模拟不同的人类模型和人工智能干预的场景,例如:
人类模型的参数存在噪声,即人类的折扣因子、奖励函数、转移函数等可能随机变化,从而影响人类的行为选择。
人类模型的结构存在误差,即人类的状态空间、行动空间、转移函数等可能与链世界不一致,从而影响人类的行为模式。
人类模型的复杂度存在差异,即人类的状态空间、行动空间、转移函数等可能比链世界更复杂或更简单,从而影响人类的行为难度。
人类模型的行为存在偏差,即人类的行为选择可能不是最优的,而是受到一些认知偏差、情绪影响、环境干扰等因素的影响。
人工智能干预的效果存在变化,即人工智能干预人类的折扣因子或奖励可能有正面的、负面的或没有效果,从而影响人类的行为反应。
 图片
图片
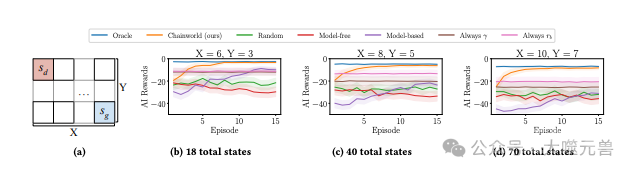
图5:Chainworld按比例缩放为大型网格世界。左边的示例网格世界。向右移动,栅格的宽度(X)和高度(Y)将增加。
作者使用了五种基准方法来与链世界进行比较,分别是:
Oracle,即人工智能知道真实的人类模型,并使用最优的干预策略。
Random,即人工智能随机选择干预或不干预,以及干预的方式和强度。
Model-free,即人工智能不使用任何人类模型,而是直接通过Q-learning来学习最优的干预策略。
Model-based,即人工智能使用观察到的人类的状态、行动和奖励来估计人类的转移函数,然后使用确定性等价来求解最优的干预策略。
Always 𝛾,即人工智能总是干预人类的折扣因子,不考虑人类的状态和行动。
Always 𝑟𝑏,即人工智能总是干预人类的奖励函数,不考虑人类的状态和行动。
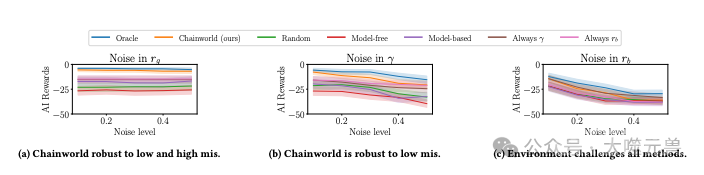 图片
图片
图6:稳健性实验示例。Chainworld对所有级别的错误指定都是稳健的(图6a),对低级别错误指定都稳健,并在高级别上进行维护(图6b),包括oracle在内的所有方法都难以在图6c中表现良好。附录D.1和附录E.3中分别列出了所有环境的详细信息和图表。
作者使用了人工智能在第六个回合中获得的奖励作为评价指标,来衡量人工智能干预的性能。作者发现链世界在大多数情况下,都可以达到或接近Oracle的性能,即使在一些极端的情况下,它也可以保持一定的水平。作者还发现链世界在低水平的模型误差下,具有很强的鲁棒性,而在高水平的模型误差下,也可以维持一定的性能。作者还发现,链世界在一些与链世界等价的人类模型下,可以完全复制Oracle的性能,证明了链世界的等价性的有效性。作者还发现,链世界在一些具有行为意义的人类模型下,可以表现出与人类的行为模式一致的干预策略,证明了链世界的解释性的有效性。
总结一下,这篇论文提出了一种行为模型强化学习(BMRL)的框架,用于让人工智能干预人类在摩擦性任务中的行为。作者提出了一种新的人类模型,称为链世界(chainworld),用于描述人类在摩擦性任务中的行为。作者引入了一种基于BMRL的人类模型之间的等价性的概念,用于判断不同的人类模型是否会导致相同的人工智能干预策略。作者通过实验分析了链世界的鲁棒性,即当真实的人类模型与链世界不完全匹配或不等价时,人工智能使用链世界进行干预的性能如何。作者的研究为人工智能干预人类行为提供了一种简单而有效的方法,也为人类行为的理解和解释提供了一种有用的工具。
这篇论文的质量和意义是显而易见的,它在人工智能和行为科学的交叉领域做出了重要的贡献。它不仅提出了一种新颖的人类模型和人工智能干预的框架,而且提供了一系列的理论证明和实验验证,展示了其有效性和鲁棒性。它也为未来的研究提供了一些有趣的方向和挑战,例如进行用户研究、考虑人工智能干预的伦理问题、测试链世界的鲁棒性、放松一些简化的假设,以及探索更多样的人工智能干预方式。这篇论文值得我们认真阅读和思考,也值得我们借鉴和应用,以期在人工智能和人类的协作和互动中,实现更好的效果和满意度。(END)
参考资料:https://arxiv.org/abs/2401.14923




还没有评论,来说两句吧...