

如果你曾经使用过Pandas处理表格数据,你可能会熟悉导入数据、清洗和转换的过程,然后将其用作模型的输入。然而,当你需要扩展和将代码投入生产时,你的Pandas管道很可能开始崩溃并运行缓慢。在这篇文章中,笔者将分享2个技巧,帮助你让Pandas代码快得离谱,提升数据处理效率并避免常见的陷阱。

技巧1:矢量化操作
在Pandas中,矢量化操作是一种强大的工具,它可以用一种更简洁和高效的方式处理整个数据框的列,而不是逐行循环。
它是如何工作的?
广播是矢量化操作的一个关键要素,它允许您直观地操作具有不同形状的对象。
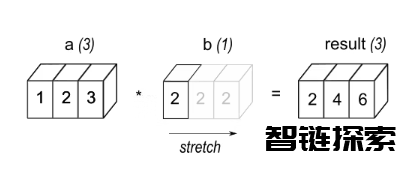
eg1: 具有3个元素的数组a与标量b相乘,得到与Source形状相同的数组。
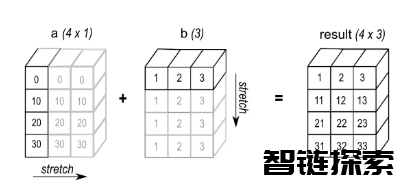
eg2: 在进行加法运算时,将形状为(4,1)的数组a与形状为(3,)的数组b相加,结果会得到一个形状为(4,3)的数组。
关于这一点已经有很多文章,并且在深度学习中,大规模的矩阵乘法是非常常见的。在本文中,我们将利用两个简短的例子上进行讨论。
首先,假设您想要计算给定整数在列中出现的次数。以下是 2 种可能的方法。
现在假设有一个DataFrame带有日期列并希望将其偏移给定的天数。使用矢量化操作计算如下:
技巧2:迭代
「for循环」
第一个也是最直观的迭代方法是使用Python for循环。
「apply」
在 df.apply 的每次迭代中,提供的可调用函数获取一个 Series,其索引为 df.columns,其值是行的。这意味着 pandas 必须在每个循环中生成该序列,这是昂贵的。为了降低成本,最好对您知道将使用的 df 子集调用 apply,如下所示:
「列表组合+itertuples」
使用itertuples与列表相结合进行迭代肯定会更好。itertuples生成带有行数据的(命名)元组。
「列表组合+zip」
zip接受可迭代对象并生成元组,其中第i个元组按顺序包含所有给定可迭代对象的第i个元素。
「列表组合+to_dict」
「缓存」
除了我们讨论的迭代技术之外,另外两种方法可以帮助提高代码的性能:缓存和并行化。如果使用相同的参数多次调用 pandas 函数,缓存会特别有用。例如,如果remove_words应用于具有许多重复值的数据集,您可以使用它functools.lru_cache来存储函数的结果并避免每次都重新计算它们。要使用lru_cache,只需将@lru_cache装饰器添加到 的声明中remove_words,然后使用您首选的迭代方法将该函数应用于您的数据集。这可以显着提高代码的速度和效率。以下面的代码为例:
添加此装饰器会生成一个函数,该函数会“记住”之前遇到的输入的输出,从而无需再次运行所有代码。
「并行化」
最后一张王牌是使用 pandarallel 跨多个独立的 df 块并行化我们的函数调用。该工具易于使用:您只需导入并初始化它,然后将所有 .applys 更改为 .parallel_applys。




还没有评论,来说两句吧...