

视频场景图生成(VidSGG)旨在识别视觉场景中的对象并推断它们之间的视觉关系。
该任务不仅需要全面了解分散在整个场景中的每个对象,还需要深入研究它们在时序上的运动和交互。
最近,来自中山大学的研究人员在人工智能顶级期刊IEEE T-IP上发表了一篇论文,进行了相关任务的探索并发现:每对物体组合及其它们之间的关系在每个图像内具有空间共现相关性,并且在不同图像之间具有时间一致性/转换相关性。

论文链接:https://arxiv.org/abs/2309.13237
基于这些先验知识,研究人员提出了一种基于时空知识嵌入的Transformer(STKET)将先验时空知识纳入多头交叉注意机制中,从而学习更多有代表性的视觉关系表示。
具体来说,首先以统计方式学习空间共现和时间转换相关性;然后,设计了时空知识嵌入层对视觉表示与知识之间的交互进行充分探索,分别生成空间和时间知识嵌入的视觉关系表示;最后,作者聚合这些特征,以预测最终的语义标签及其视觉关系。
大量实验表明,文中提出的框架大幅优于当前竞争算法。目前,该论文已经被接收。
论文概述
随着场景理解领域的快速发展,许多研究者们开始尝试利用各种框架解决场景图生成(Scene Graph Generation, SGG)任务,并已取得了不俗的进展。
但是,这些方法往往只考虑单张图像的情况,忽略了时序中存在着的大量的上下文信息,导致现有大部分场景图生成算法在无法准确地识别所给定的视频中包含的动态视觉关系。
因此,许多研究者致力于开发视频场景图生成(Video Scene Graph Generation, VidSGG)算法来解决这个问题。
目前的工作主要关注从空间和时间角度聚合对象级视觉信息,以学习对应的视觉关系表示。
然而,由于各类物体与交互动作的视觉外表方差大以及视频收集所导致的视觉关系显著的长尾分布,单纯的仅用视觉信息容易导致模型预测错误的视觉关系。
针对上述问题,研究人员做了以下两方面的工作:
首先,提出挖掘训练样本中包含的先验时空知识用以促进视频场景图生成领域。其中,先验时空知识包括:
1)空间共现相关性:某些对象类别之间的关系倾向于特定的交互。
2)时间一致性/转换相关性:给定对的关系在连续视频剪辑中往往是一致的,或者很有可能转换到另一个特定关系。
其次,提出了一种新颖的基于时空知识嵌入的Transformer(Spatial-Temporal Knowledge-Embedded Transformer, STKET)框架。
该框架将先验时空知识纳入多头交叉注意机制中,从而学习更多有代表性的视觉关系表示。根据在测试基准上得到的比较结果可以发现,研究人员所提出的STKET框架优于以前的最先进方法。

图1:由于视觉外表多变和视觉关系的长尾分布,导致视频场景图生成充满挑战
基于时空知识嵌入的Transformer
时空知识表示
在推断视觉关系时,人类不仅利用视觉线索,还利用积累的先验知识[1, 2]。受此启发,研究人员提出直接从训练集中提取先验时空知识,以促进视频场景图生成任务。
其中,空间共现相关性具体表现为当给定物体组合后其视觉关系分布将高度倾斜(例如,「人」与「杯子」之间的视觉关系的分布明显不同于「狗」与「玩具」之间的分布)和时间转移相关性具体表现为当给定前一时刻的视觉关系后各个视觉关系的转换概率将大幅变化(例如,当已知前一时刻的视觉关系为「吃」时,下一时刻视觉关系转移为「书写」的概率大幅下降)。
如图2所示,可以直观地感受到给定物体组合或之前的视觉关系后,预测空间可以被大幅的缩减。
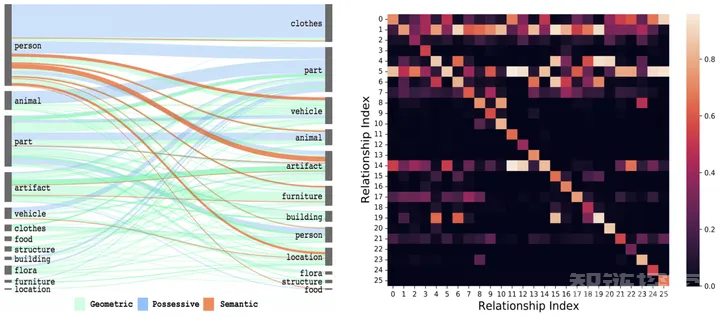
图2:视觉关系的空间共现概率[3]与时间转移概率
具体而言,对于第i类物体与第j类物体的组合,以及其上一时刻为第x类关系的情况,首先通过统计的方式获得其对应的空间共现概率矩阵E^{i,j}和时间转移概率矩阵Ex^{i,j}。
接着,将其输入到全连接层中得到对应的特征表示,并利用对应的目标函数确保模型所学到的的知识表示包含对应的先验时空知识。
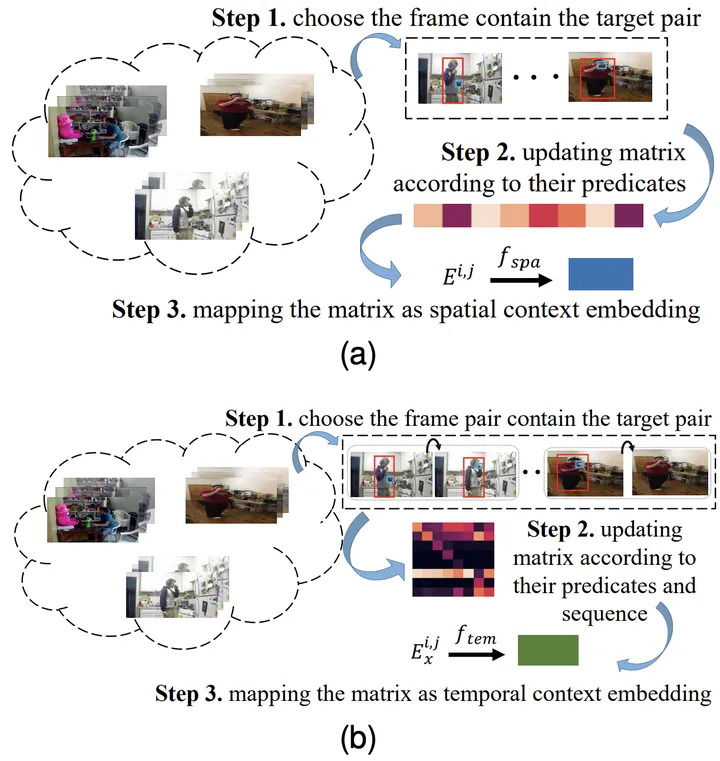
图3:学习空间(a)和时间(b)知识表示的过程
知识嵌入注意力层
空间知识通常包含有关实体之间的位置、距离和关系的信息。另一方面,时间知识涉及动作之间的顺序、持续时间和间隔。
鉴于它们独特的属性,单独处理它们可以允许专门的建模更准确地捕获固有模式。
因此,研究人员设计了时空知识嵌入层,彻底探索视觉表示与时空知识之间的相互作用。
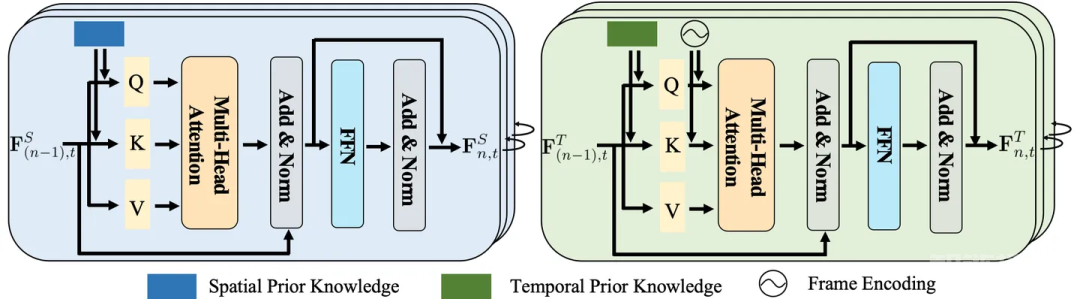
图4:空间(左侧)和时间(右侧)知识嵌入层
时空聚合模块
如前所述,空间知识嵌入层探索每个图像内的空间共现相关性,时间知识嵌入层探索不同图像之间的时间转移相关性,以此充分探索了视觉表示和时空知识之间的相互作用。
尽管如此,这两层忽略了长时序的上下文信息,而这对于识别大部分动态变化的视觉关系具有帮助。
为此,研究人员进一步设计了时空聚合(STA)模块来聚合每个对象对的这些表示,以预测最终的语义标签及其关系。它将不同帧中相同主客体对的空间和时间嵌入关系表示作为输入。
具体来说,研究人员将同一对象对的这些表示连接起来以生成上下文表示。
然后,为了在不同帧中找到相同的主客体对,采用预测的对象标签和IoU(即并集交集)来匹配帧中检测到的相同主客体对。
最后,考虑到帧中的关系在不同批次中有不同的表示,选择滑动窗口中最早出现的表示。
实验结果
为了全面评估所提出的框架的性能,研究人员除了对比现有的视频场景图生成方法(STTran, TPI, APT)外,也选取了先进的图像场景图生成方法(KERN, VCTREE, ReIDN, GPS-Net)进行比较。
其中,为确保对比的公平,图像场景图生成方法通过对每一帧图像进行识别,从而达到对所给定视频生成对应场景图的目标。
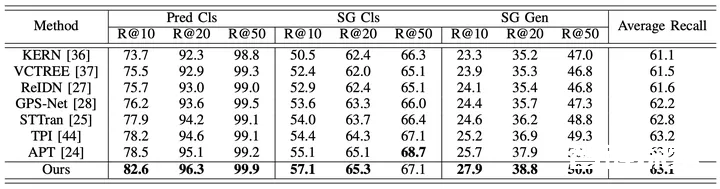
图5:在Action Genome数据集上以Recall为评价指标的实验结果

图6:在Action Genome数据集上以mean Recall为评价指标的实验结果




还没有评论,来说两句吧...