


大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错误答案的合成数据。
在 AAAI 2024 上,小红书搜索算法团队提出了一个创新框架,在蒸馏大模型推理能力的过程中充分利用负样本知识。负样本,即那些在推理过程中未能得出正确答案的数据,虽常被视为无用,实则蕴含着宝贵的信息。
论文提出并验证了负样本在大模型蒸馏过程中的价值,构建一个模型专业化框架:除了使用正样本外,还充分利用负样本来提炼 LLM 的知识。该框架包括三个序列化步骤,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC),涵盖从训练到推理的全阶段过程。通过一系列广泛的实验,我们展示了负向数据在 LLM 知识蒸馏中的关键作用。
一、背景
如今,在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。然而,思维链已被证明是千亿级参数模型才具有的涌现能力。这些模型的繁重计算需求和高推理成本,阻碍了它们在资源受限场景中的应用。因此,我们研究的目标是使小模型能够进行复杂的算术推理,以便在实际应用中进行大规模部署。
知识蒸馏提供了一种有效的方法,可以将 LLMs 的特定能力迁移到更小的模型中。这个过程也被称为模型专业化(model specialization),它强制小模型专注于某些能力。先前的研究利用 LLMs 的上下文学习(ICL)来生成数学问题的推理路径,将其作为训练数据,有助于小模型获得复杂推理能力。然而,这些研究只使用了生成的具有正确答案的推理路径(即正样本)作为训练样本,忽略了在错误答案(即负样本)的推理步骤中有价值的知识。
 图片
图片
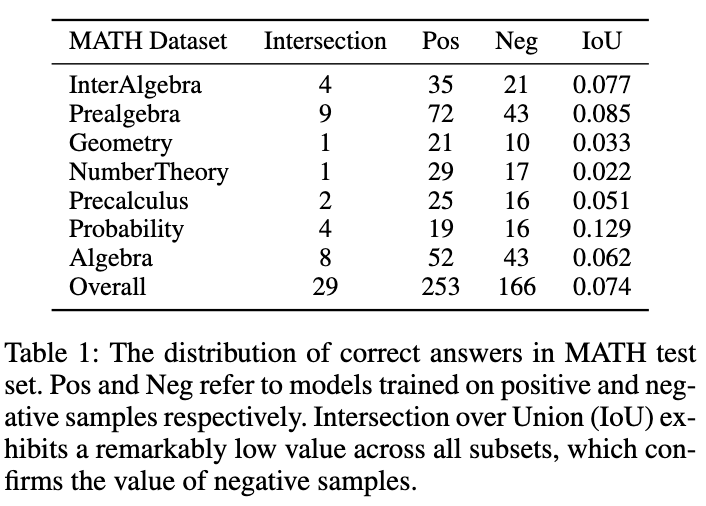
如图所示,表 1 展示了一个有趣的现象:分别在正、负样本数据上训练的模型,在 MATH 测试集上的准确答案重叠非常小。尽管负样本训练的模型准确性较低,但它能够解决一些正样本模型无法正确回答的问题,这证实了负样本中包含着宝贵的知识。此外,负样本中的错误链路能够帮助模型避免犯类似错误。另一个我们应该利用负样本的原因是 OpenAI 基于 token 的定价策略。即使是 GPT-4,在 MATH 数据集上的准确性也低于 50%,这意味着如果仅利用正样本知识,大量的 token 会被浪费。因此,我们提出:相比于直接丢弃负样本,更好的方式是从中提取和利用有价值的知识,以增强小模型的专业化。
模型专业化过程一般可以概括为三个步骤:
1)思维链蒸馏(Chain-of-Thought Distillation),使用 LLMs 生成的推理链训练小模型。
2)自我增强(Self-Enhancement),进行自蒸馏或数据自扩充,以进一步优化模型。
3)自洽性(Self-Consistency)被广泛用作一种有效的解码策略,以提高推理任务中的模型性能。
在这项工作中,我们提出了一种新的模型专业化框架,该框架可以全方位利用负样本,促进从 LLMs 提取复杂推理能力。
我们首先设计了负向协助训练(NAT)方法,其中 dual-LoRA 结构被设计用于从正向、负向两方面获取知识。作为一个辅助模块,负向 LoRA 的知识可以通过校正注意力机制,动态地整合到正向 LoRA 的训练过程中。
对于自我增强,我们设计了负向校准增强(NCE),它将负向输出作为基线,以加强关键正向推理链路的蒸馏。
除了训练阶段,我们还在推理过程中利用负向信息。传统的自洽性方法将相等或基于概率的权重分配给所有候选输出,导致投票出一些不可靠的答案。为了缓解该问题,提出了动态自洽性(ASC)方法,在投票前进行排序,其中排序模型在正负样本上进行训练的。
二、方法
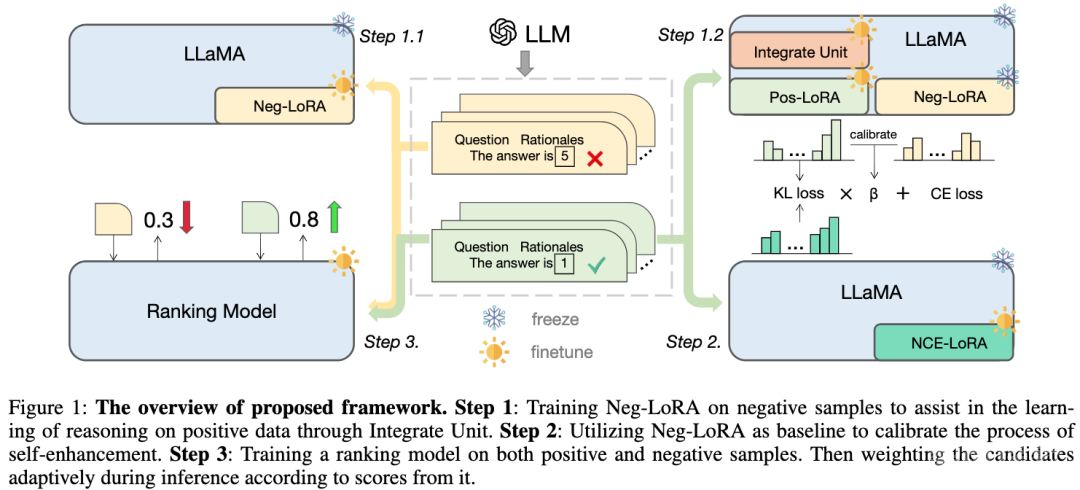
我们提出的框架以 LLaMA 为基础模型,主要包含三个部分,如图所示:
步骤 1 :对负向 LoRA 进行训练,通过合并单元帮助学习正样本的推理知识;
步骤 2 :利用负向 LoRA 作为基线来校准自我增强的过程;
步骤 3 :在正样本和负样本上训练排名模型,在推理过程中根据其得分,自适应地对候选推理链路进行加权。
 图片
图片
2.1 负向协助训练(NAT)
我们提出了一个两阶段的负向协助训练(NAT)范式,分为负向知识吸收与动态集成单元两部分:
2.1.1 负向知识吸收
通过在负数据
上最大化以下期望,负样本的知识被 LoRA θ
吸收。在这个过程中,LLaMA 的参数保持冻结。
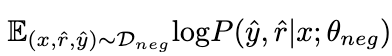 图片
图片
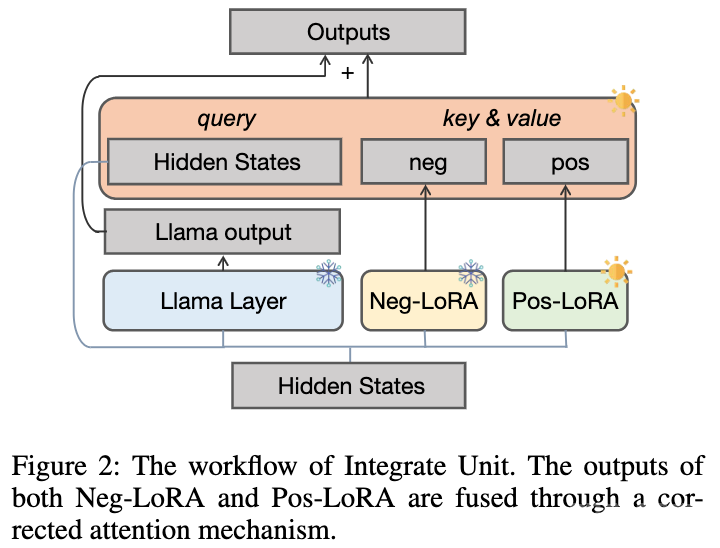
2.1.2 动态集成单元
由于无法预先确定 θ
擅长哪些数学问题,我们设计了如下图所示的动态集成单元,以便在 学习正样本知识的过程中,动态集成来自 θ
的知识:
 图片
图片
我们冻结 θ
以防止内部知识被遗忘,并额外引入正 LoRA 模块 θ 。理想情况下,我们应该正向集成正负 LoRA 模块(在每个 LLaMA 层中输出表示为 与 ),以补充正样本中所缺乏但对应 所具有的有益知识。当 θ
包含有害知识时,我们应该对正负 LoRA 模块进行负向集成,以帮助减少正样本中可能的不良行为。
我们提出了一种纠正注意力机制来实现这一目标,如下所示:
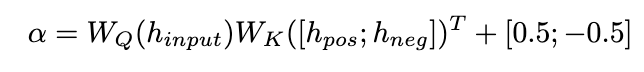 图片
图片
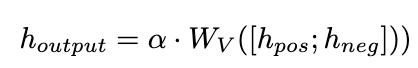 图片
图片
我们使用
作为查询来计算 和 的注意力权重。通过在添加校正项 [0.5;-0.5], 的注意力权重被限制在 [-0.5,0.5] 的范围内,从而实现了在正、负两个方向上自适应地集成来自 的知识的效果。最终,
和 LLaMA 层输出的总和形成了动态集成单元的输出。
2.2 负向校准增强(NCE)
为了进一步增强模型的推理能力,我们提出了负校准增强(NCE),它使用负知识来帮助自我增强过程。我们首先使用 NAT 为中的每个问题生成对作为扩充样本,并将它们补充到训练数据集中。对于自蒸馏部分,我们注意到一些样本可能包含更关键的推理步骤,对提升模型的推理能力至关重要。我们的主要目标是确定这些关键的推理步骤,并在自蒸馏过程中加强对它们的学习。
考虑到 NAT 已经包含了 θ
的有用知识,使得 NAT 比 θ
推理能力更强的因素,隐含在两者之间不一致的推理链路中。因此,我们使用 KL 散度来测量这种不一致性,并最大化该公式的期望:
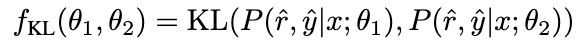 图片
图片
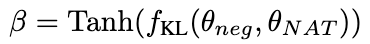 图片
图片
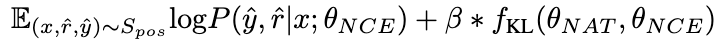 图片
图片
β 值越大,表示两者之间的差异越大,意味着该样本包含更多关键知识。通过引入 β 来调整不同样本的损失权重,NCE 将能够选择性地学习并增强 NAT 中嵌入的知识。
2.3 动态自洽性(ASC)
自洽性(SC)对于进一步提高模型在复杂推理中的表现是有效的。然而,当前的方法要么为每个候选者分配相等的权重,要么简单地基于生成概率分配权重。这些策略无法在投票阶段根据 (rˆ, yˆ) 的质量调整候选权重,这可能会使正确候选项不易被选出。为此,我们提出了动态自洽性方法(ASC),它利用正负数据来训练排序模型,可以自适应地重新配权候选推理链路。
2.3.1 排序模型训练
理想情况下,我们希望排序模型为得出正确答案的推理链路分配更高的权重,反之亦然。因此,我们用以下方式构造训练样本:
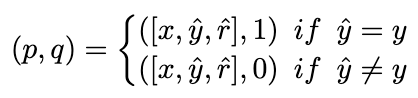 图片
图片
并使用 MSE loss 去训练排序模型:
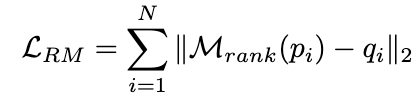 图片
图片
2.3.2 加权策略
我们将投票策略修改为以下公式,以实现自适应地重新加权候选推理链路的目标:
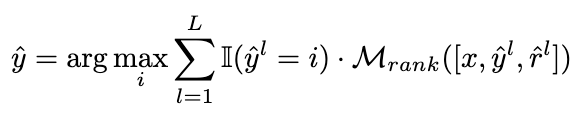 图片
图片
下图展示了 ASC 策略的流程:
 图片
图片
从知识迁移的角度来看,ASC 实现了对来自 LLMs 的知识(正向和负向)的进一步利用,以帮助小模型获得更好的性能。
三、实验
本研究专注于具有挑战性的数学推理数据集 MATH,该数据集共有 12500 个问题,涉及七个不同的科目。此外,我们还引入了以下四个数据集来评估所提出的框架对分布外(OOD)数据的泛化能力:GSM8K、ASDiv、MultiArith和SVAMP。
对于教师模型,我们使用 Open AI 的 gpt-3.5-turbo 和 gpt-4 API来生成推理链。对于学生模型,我们选择 LLaMA-7b。
在我们的研究中有两种主要类型的基线:一种为大语言模型(LLMs),另一种则基于 LLaMA-7b。对于 LLMs,我们将其与两种流行的模型进行比较:GPT3 和 PaLM。对于 LLaMA-7b,我们首先提供我们的方法与三种设置进行比较:Few-shot、Fine-tune(在原始训练样本上)、CoT KD(思维链蒸馏)。在从负向角度学习方面,还将包括四种基线方法:MIX(直接用正向和负向数据的混合物训练 LLaMA)、CL(对比学习)、NT(负训练)和 UL(非似然损失)。
3.1 NAT 实验结果
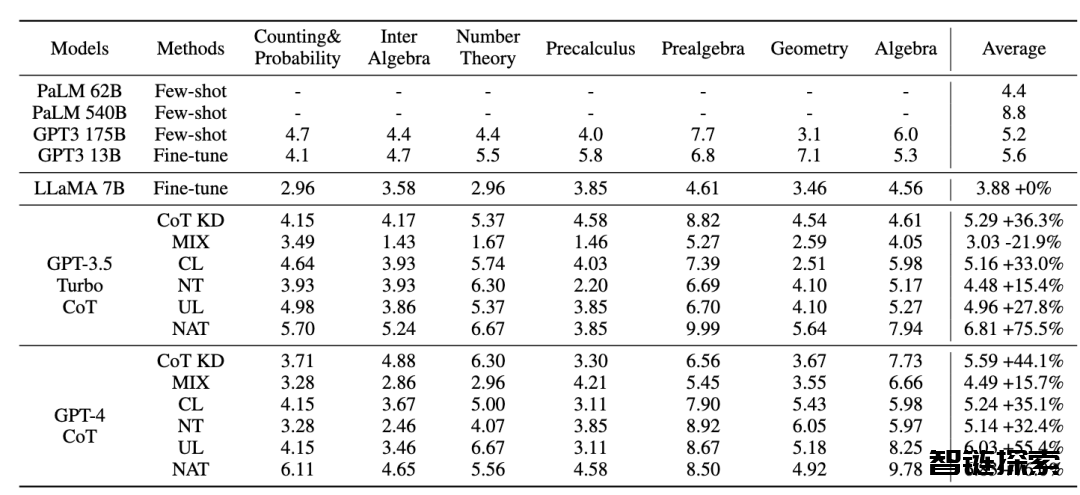
所有的方法都使用了贪婪搜索(即温度 = 0),NAT 的实验结果如图所示,表明所提出的 NAT 方法在所有基线上都提高了任务准确性。
从 GPT3 和 PaLM 的低值可以看出,MATH 是一个非常困难的数学数据集,但 NAT 仍然能够在参数极少的情况下表现突出。与在原始数据上进行微调相比,NAT 在两种不同的 CoT 来源下实现了约 75.75% 的提升。与 CoT KD 在正样本上的比较,NAT 也显著提高了准确性,展示了负样本的价值。
对于利用负向信息基线,MIX 的低性能表明直接训练负样本会使模型效果很差。其他方法也大多不如 NAT,这表明在复杂推理任务中仅在负方向上使用负样本是不够的。
 图片
图片
3.2 NCE 实验结果
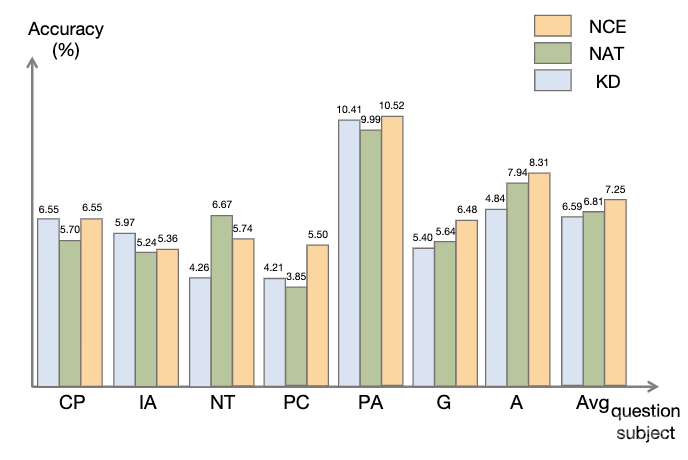
如图所示,与知识蒸馏(KD)相比,NCE 实现了平均 10%(0.66) 的进步,这证明了利用负样本提供的校准信息进行蒸馏的有效性。与 NAT 相比,尽管 NCE 减少了一些参数,但它依然有 6.5% 的进步,实现压缩模型并提高性能的目的。
 图片
图片
3.3 ASC 实验结果
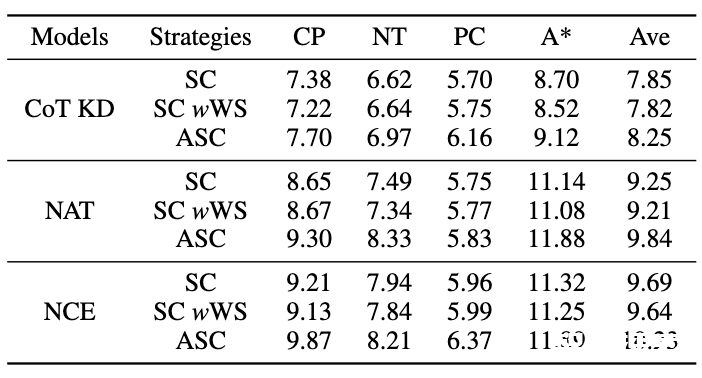
为了评估 ASC,我们将其与基础 SC 和 加权(WS)SC 进行比较,使用采样温度 T = 1 生成了 16 个样本。如图所示,结果表明,ASC 从不同样本聚合答案,是一种更有前景的策略。
 图片
图片
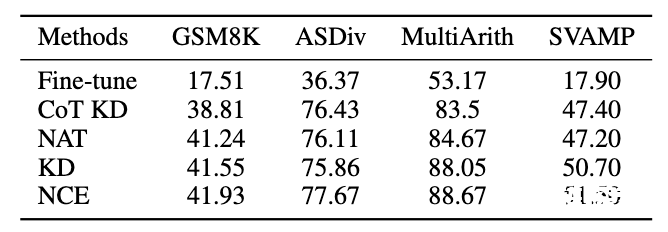
3.4 泛化性实验结果
除了 MATH 数据集,我们评估了框架在其他数学推理任务上的泛化能力,实验结果如下。
 图片
图片
四、结语
本项工作探讨了利用负样本从大语言模型中提炼复杂推理能力,迁移到专业化小模型的有效性。小红书搜索算法团队提出了一个全新的框架,由三个序列化步骤组成,并在模型专业化的整个过程中充分利用负向信息。负向协助训练(NAT)可以从两个角度提供更全面地利用负向信息的方法。负向校准增强(NCE)能够校准自蒸馏过程,使其更有针对性地掌握关键知识。基于两种观点训练的排序模型可以为答案聚合分配更适当的权重,以实现动态自洽性(ASC)。大量实验表明,我们的框架可以通过生成的负样本来提高提炼推理能力的有效性。
论文地址:https://arxiv.org/abs/2312.12832
五、作者简介
李易为:
现博士就读于北京理工大学,小红书社区搜索实习生,在 AAAI、ACL、EMNLP、NAACL、NeurIPS、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文,主要研究方向为大语言模型蒸馏与推理、开放域对话生成等。袁沛文:
现博士就读于北京理工大学,小红书社区搜索实习生,在 NeurIPS、AAAI 等发表多篇一作论文,曾获 DSTC11 Track 4 第二名。主要研究方向为大语言模型推理与评测。冯少雄:
负责小红书社区搜索向量召回。在 AAAI、EMNLP、ACL、NAACL、KBS 等机器学习、自然语言处理领域顶级会议/期刊上发表数篇论文。
道玄(潘博远):
小红书交易搜索负责人。在NeurIPS、ICML、ACL 等机器学习和自然语言处理领域顶级会议上发表数篇一作论文,在斯坦福机器阅读竞赛 SQuAD 排行榜上获得第二名,在斯坦福自然语言推理排行榜上获得第一名。




还没有评论,来说两句吧...