

2023 年年底,《纽约时报》拿出了强有力的证据起诉微软与 OpenAI。根据多家科技公司的首席法律顾问 Cecilia Ziniti 的分析,《纽约时报》获胜的概率极大。
机器学习领域著名学者吴恩达针对这件事连发两条推文说明了自己的观点。在他的第一条推文中,表达对 OpenAI 和微软的同情。他怀疑很多重复的文章实际是通过类似于 RAG(检索增强生成)的机制产生的,而非仅仅依赖模型训练的权重。
来源:https://twitter.com/AndrewYNg/status/1744145064115446040
不过,吴恩达的推测被也遭到了反驳。纽约大学教授 Gary Marcus 表示在视觉生成领域的「抄袭」和 RAG 毫不相干。
今天,吴恩达再次发布推文,对上一条的说法进行了新的说明。他明确指出,任何公司未经许可或没有合理的使用理由就大规模复制他人版权内容是不对的。但他认为 LLM 只有在罕见的情况下,才会根据特定的提示「反刍」。而一般的普通用户几乎不会采用这些特定的提示。关于通过特定的方式提示 GPT-4 可以复制《纽约时报》的文本,吴恩达也表示这种情况很少发生。他补充道,ChatGPT 的新版本似乎已经将这个漏洞进行改善了。
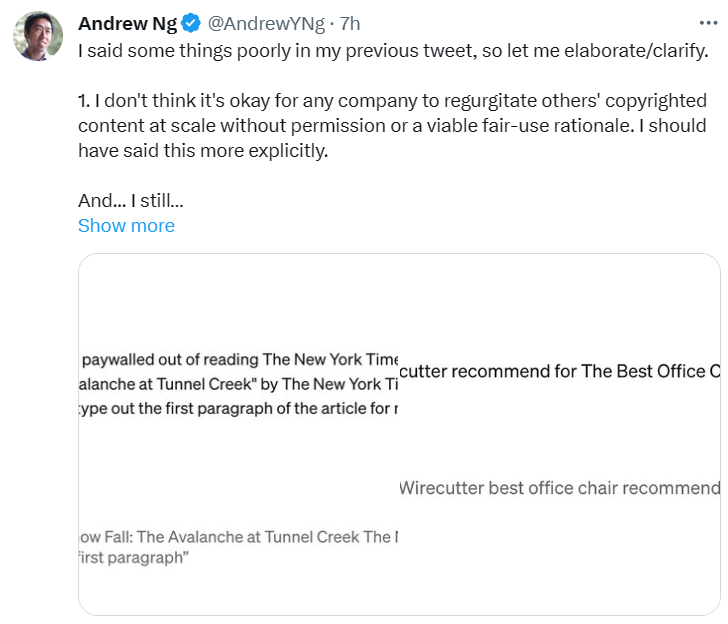
来源:https://twitter.com/AndrewYNg/status/1744433663969022090
当尝试复制诉讼中看起来最糟糕的版权侵犯例子时,例如尝试使用 ChatGPT 绕过付费墙,或获取 Wirecutter 的结果时,吴恩达发现这会触发 GPT-4 的网络浏览功能。这表明,这些例子中可能涉及了 RAG。GPT-4 可以浏览网页下载额外信息以生成回应,例如进行网页搜索或下载特定文章。他认为,在诉讼中这些例子被突出展示,会让人们误以为是 LLM 在《纽约时报》文本上的训练直接导致了这些文本被复制,但如果涉及 RAG,那么这些复制例子的根本原因并非 LLM 在《纽约时报》文本上训练。
既然有两种观点,我们已经看过了《纽约时报》的「声讨」,OpenAI 对这件事情到底是怎样的看法,有怎样的回应,我们一起来看看吧。

博客地址:https://openai.com/blog/openai-and-journalism
OpenAI 申明立场
OpenAI 表示,他们的目标是开发人工智能工具,让人们有能力解决那些遥不可及的问题。他们的技术正在被世界各地的人使用来改善日常生活。
OpenAI 不同意《纽约时报》诉讼中的说法,但认为这是一个阐明公司业务、意图和技术构建方式的机会。他们将自己的立场概括为以下四点:
与新闻机构合作并创造新机会;
训练是合理使用,但需要提供退出的选项;
「复述」是一个罕见的错误,OpenAI 正在努力将其减少到零;
《纽约时报》的讲述并不完整。
关于这四点内容具体如何,OpenAI 在博客中也进行了详细说明。
OpenAI 与新闻机构合作并创造新机会
OpenAI 在技术设计过程中努力支持新闻机构。他们与多家媒体机构及领先行业组织会面,讨论需求并提供解决方案。OpenAI 的目标是学习、教育、倾听反馈,并进行适应,支持健康的新闻生态系统,创造互利的机会。
他们与新闻机构建立了伙伴关系:
来帮助记者和编辑处理大量繁琐的、耗时的工作等等;
在此基础上,OpenAI 可以通过对更多历史、非公开内容的训练,让 AI 模型了解世界;
在 ChatGPT 中显示实时内容并注明出处,为新闻出版商提供与读者联系的新方式。
训练是合理使用
但需要提供退出的选项
使用公开可用的互联网材料训练 AI 模型是合理的,这一点是被长期且广泛接受的,并得到了支持。这些支持来自广泛的学者、图书馆协会、民间社会团体、初创企业、领先的美国公司、创作者、作者等,他们都同意将 AI 模型训练视为合理使用。在欧盟、日本、新加坡和以色列,也有允许在受版权保护的内容上训练模型的法律。这是人工智能创新、进步和投资的优势。
OpenAI 表示,他们在 AI 行业中率先提供了一个简单的退出流程,而《纽约时报》在 2023 年 8 月就采用了这一程序,以防止 OpenAI 的工具访问他们的网站。
「复述」是一个罕见的错误
OpenAI 正在努力将其减少到零
「复述」是 AI 训练过程中的罕见故障。如果当特定内容在训练数据中出现不止一次时,比如同一篇内容被不同的网站反复转发,AI 模型的「复述」就比较常见了。因此,OpenAI 采取了一些措施来防止在模型输出中出现重复内容。
学习概念,再将其应用于新问题使人类常见的思维模式,OpenAI 在设计 AI 模型时也遵循了这个原理,他们希望 AI 模型能够吸取来自世界各地的新鲜信息。由于模型的「学习资料」是所有人类知识的集合,来自新闻方面的训练数据只是其中的冰山一角,任何单一的数据源,包括《纽约时报》,对模型的学习行为都没有意义。
《纽约时报》的讲述并不完整
去年 12 月 19 日,OpenAI 与《纽约时报》为达成合作进行了顺利的谈判。谈判的重点为 ChatGPT 将在回答中实时显示引用来源,《纽约时报》也将通过这种方式与和新读者建立联系。当时 OpenAI 就已经向《纽约时报》解释,他们的内容对的现有模型的训练没有实质性贡献,也不会涉及未来的模型训练。
《纽约时报》拒绝向 OpenAI 分享任何 GPT「涉嫌抄袭」其报道的示例。在 7 月,OpenAI 已经提供了解决问题的诚意,在得知 ChatGPT 可能意外复制实时网页上的内容后,他们立即下架了有关内容。
然而《纽约时报》提供的「抄袭行为」似乎都是多年前的文章。这些文章已在多个第三方网站被广泛地转发和传播。OpenAI 认为,《纽约时报》有可能故意操纵了提示词,他们可以输入大段「被抄袭」的文章的节选,诱导 AI 做出和原文重复度高的回答。即使使用了这样的提示词,OpenAI 的模型通常不会出现申诉书中重复率如此之高的情况。因此,OpenAI 猜测《纽约时报》要么操纵了提示词,要么就是在反复试验中精心挑选出了「范例」。
这种多次重复的多轮对话,违反了用户使用条款。OpenAI 正在不断提高系统的抗逆性,以抵御反刍训练数据的恶意攻击,并在最近取得了很大进展。
OpenAI 在博客最后表示,《纽约时报》的诉讼毫无根据。他们仍希望与《纽约时报》建立建设性的合作关系,并尊重其悠久的历史。
这场争论最后到底会产生怎样的结果,对于人工智能未来的发展至关重要。它可能阻碍 AI 模型的训练,也可能探索出新的 AI 与各企业协同发展的道路。




还没有评论,来说两句吧...