


译者 | 布加迪
审校 | 重楼
向量嵌入在AI中至关重要,它可以将复杂的非结构化数据转换成机器可以处理的数值向量。这些嵌入捕获数据中的语义和关系,从而实现更有效的分析和内容生成。
ChatGPT的创建者OpenAI提供了各种嵌入模型,这些模型提供高质量的向量表示,可用于包括语义搜索、聚类和异常检测在内的各种应用。这篇指南将探讨如何利用OpenAI的文本嵌入模型来构建响应迅速的智能AI系统。
什么是向量嵌入和嵌入模型?
在我们深入讨论之前,不妨先阐述几个术语。首先,什么是向量嵌入?向量嵌入是许多AI概念的基础。它是数据的数值表示,特别是非结构化数据,比如文本、视频、音频、图片及其他数字媒体。它捕获数据中的语义和关系,并为存储系统和AI模型提供一种高效的方式来解读、处理、存储和检索复杂的高维非结构化数据。
所以,如果嵌入是数据的数值表示,那么如何将数据转换成向量嵌入?这时候嵌入模型就有了用武之地。
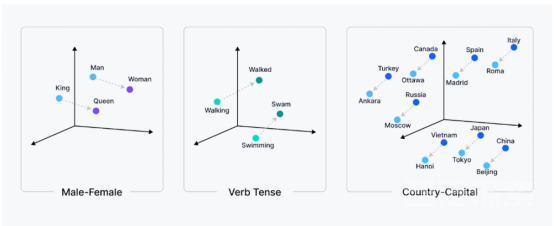
嵌入模型是一种将非结构化数据转换成向量嵌入的专用算法。它旨在学习数据中的模式和关系,然后在高维空间中表示它们。关键思想是,相似的数据片段具有相似的向量表示,并且在高维空间中彼此更接近,从而允许AI模型更有效地处理和分析数据。
比如在自然语言处理(NLP)背景下,嵌入模型可能在学习后明白单词“king”和“queen”是相关的,应该在向量空间中彼此靠近,而像“banana”这样的单词将被放在更远的位置。向量空间中的这种邻近反映了单词之间的语义关系。
嵌入模型和向量嵌入的一个常见用途在于检索增强生成(RAG)系统。RAG系统不是仅仅依赖大语言模型(LLM)中的预训练知识,而是在生成输出之前为LLM提供额外的上下文信息。这些额外的数据使用嵌入模型转换成向量嵌入,然后存储在像Milvus这样的向量数据库中。对于需要详细的、基于事实的查询响应的组织和开发人员来说,RAG是理想的选择,使得它在各个行业部门都很有价值。
OpenAI文本嵌入模型
ChatGPT背后的OpenAI公司提供了各种嵌入模型,它们非常适合处理语义搜索、聚类、推荐系统、异常检测、多样性测量和分类等任务。
鉴于OpenAI的受欢迎程度,许多开发人员可能会使用它的模型来尝试RAG概念。虽然这些概念一般适用于嵌入模型,还是不妨关注OpenAI具体提供了什么。
在谈论NLP时,一些OpenAI嵌入模型特别重要。
text-embedding-ada- 002
text-embedding-3-small
text-embedding-3-large
下表提供了这些模型之间的直接比较。
模型 | 描述 | 输出维度 | 最大输入 | 价格 |
text- embedding-3- large | 功能最强大的嵌入模型, 同时适用于英文任务和 非英文任务。 | 3072 | 8.191 | 0.13美元/100万 个token |
text- embedding-3- small | 比第二代ada嵌入模型 提高了性能。 | 1536 | 8.191 | 0.10美元/100万 个token |
text- embedding- ada - 002 | 功能最强大的第二代嵌入 模型,取代16个第一代 模型。 | 1536 | 8.191 | 0.02美元/100万 个token |
选择合适的模型
与所有事情一样,选择模型需要权衡利弊。在全身心投入其中一个模型之前,确保你清楚地了解自己想要做什么、有哪些可用的资源以及期望从生成的输出中获得哪种程度的准确性。使用RAG系统,你可能会权衡计算资源与查询响应的速度和准确性。
text- embeddings -3-large:当准确性和嵌入丰富度很重要时,这可能是首选的模型。它使用最多的CPU和内存资源(价格更昂贵),需要最长的时间来生成输出,但输出将是高质量的。典型的用例包括研究、高风险应用或处理非常复杂的文本。
text-embedding-3-small:如果你更关心速度和效率,而不是获得绝对最好的结果,该模型的资源密集程度较低,从而降低了成本,并缩短了响应时间。典型的用例包括实时应用或资源有限的情形。
text-embedding-ada-002:虽然其他两个模型是最新版本,但这是在OpenAI引入之前的主要模型。这种多功能模型在两个极端之间提供了很好的中间地带,提供了可靠的性能和合理的效率。
如何用OpenAI生成向量嵌入?
不妨逐步看看如何使用这每一种嵌入模型生成向量嵌入。无论选择哪种模型,你都需要具备几个要素才能入手,包括向量数据库。
PyMilvus是用于Milvus的Python软件开发工具包(SDK),在这种环境下很方便,因为它与所有这些OpenAI模型无缝集成。OpenAI Python库是另一个选择,它是OpenAI提供的SDK。
为了本教程,我将使用PyMilvus生成向量嵌入,并将它们存储在Zilliz Cloud中,以便进行简单的语义搜索。
Zilliz Cloud上手起来很简单:
注册一个免费的Zilliz Cloud帐户。
设置无服务器集群,并获取公共端点和API密钥。
创建一个向量集合,并插入你的向量嵌入。
对存储的嵌入进行语义搜索。
好了,现在我将解释如何为上面讨论的这三个模型生成向量嵌入。
text-embedding-ada-002text-embedding-ada-002
使用text-embedding-ada-002生成向量嵌入,并将其存储在Zilliz Cloud中进行语义搜索:
from pymilvus.model.dense import OpenAIEmbeddingFunction from pymilvus import MilvusClient OPENAI_API_KEY = "your-openai-api-key" ef = OpenAIEmbeddingFunction("text-embedding-ada-002", api_key=OPENAI_API_KEY) docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England." ] # Generate embeddings for documents docs_embeddings = ef(docs) queries = ["When was artificial intelligence founded", "Where was Alan Turing born?"] # Generate embeddings for queries query_embeddings = ef(queries) # Connect to Zilliz Cloud with Public Endpoint and API Key client = MilvusClient( uri=ZILLIZ_PUBLIC_ENDPOINT, token=ZILLIZ_API_KEY) COLLECTION = "documents" if client.has_collection(collection_name=COLLECTION): client.drop_collection(collection_name=COLLECTION) client.create_collection( collection_name=COLLECTION, dimension=ef.dim, auto_id=True) for doc, embedding in zip(docs, docs_embeddings): client.insert(COLLECTION, {"text": doc, "vector": embedding}) results = client.search( collection_name=COLLECTION, data=query_embeddings, consistency_level="Strong", output_fields=["text"])1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.text-embedding-3-small
使用text-embedding-3-small生成向量嵌入,并将其存储在Zilliz Cloud中进行语义搜索:
from pymilvus import model, MilvusClient OPENAI_API_KEY = "your-openai-api-key" ef = model.dense.OpenAIEmbeddingFunction( model_name="text-embedding-3-small", api_key=OPENAI_API_KEY, ) # Generate embeddings for documents docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England." ] docs_embeddings = ef.encode_documents(docs) # Generate embeddings for queries queries = ["When was artificial intelligence founded", "Where was Alan Turing born?"] query_embeddings = ef.encode_queries(queries) # Connect to Zilliz Cloud with Public Endpoint and API Key client = MilvusClient( uri=ZILLIZ_PUBLIC_ENDPOINT, token=ZILLIZ_API_KEY) COLLECTION = "documents" if client.has_collection(collection_name=COLLECTION): client.drop_collection(collection_name=COLLECTION) client.create_collection( collection_name=COLLECTION, dimension=ef.dim, auto_id=True) for doc, embedding in zip(docs, docs_embeddings): client.insert(COLLECTION, {"text": doc, "vector": embedding}) results = client.search( collection_name=COLLECTION, data=query_embeddings, consistency_level="Strong", output_fields=["text"])1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.43.44.text-embedding-3-large
使用text-embedding-3-large生成向量嵌入,并将其存储在Zilliz Cloud中进行语义搜索:
from pymilvus.model.dense import OpenAIEmbeddingFunction from pymilvus import MilvusClient OPENAI_API_KEY = "your-openai-api-key" ef = OpenAIEmbeddingFunction("text-embedding-3-large", api_key=OPENAI_API_KEY) docs = [ "Artificial intelligence was founded as an academic discipline in 1956.", "Alan Turing was the first person to conduct substantial research in AI.", "Born in Maida Vale, London, Turing was raised in southern England." ] # Generate embeddings for documents docs_embeddings = ef(docs) queries = ["When was artificial intelligence founded", "Where was Alan Turing born?"] # Generate embeddings for queries query_embeddings = ef(queries) # Connect to Zilliz Cloud with Public Endpoint and API Key client = MilvusClient( uri=ZILLIZ_PUBLIC_ENDPOINT, token=ZILLIZ_API_KEY) COLLECTION = "documents" if client.has_collection(collection_name=COLLECTION): client.drop_collection(collection_name=COLLECTION) client.create_collection( collection_name=COLLECTION, dimension=ef.dim, auto_id=True) for doc, embedding in zip(docs, docs_embeddings): client.insert(COLLECTION, {"text": doc, "vector": embedding}) results = client.search( collection_name=COLLECTION, data=query_embeddings, consistency_level="Strong", output_fields=["text"])1.2.3.4.5.6.7.8.9.10.11.12.13.14.15.16.17.18.19.20.21.22.23.24.25.26.27.28.29.30.31.32.33.34.35.36.37.38.39.40.41.42.结论
虽然本教程只是触及表面,但这些脚本足以让你开始上手向量嵌入。值得一提的是,这些绝不是唯一可用的模型。这份全面的AI模型列表都与Milvus协同工作。不管你的AI用例是什么,你可能都会找到一个可以满足需求的模型。
如果想进一步了解Milvus、Zilliz Cloud、RAG系统和向量数据库等方面,敬请访问Zilliz.com。
原文标题:Beginner’s Guide to OpenAI Text Embedding Models,作者:Jason Myers
链接:https://thenewstack.io/beginners-guide-to-openai-text-embedding-models/。




还没有评论,来说两句吧...